









摘要:ChatGPT重新点燃了AI,然后OpenAI却没有向我们开放ChatGPT,虽然有些人通过了一些手段注册了账号,但是不久就被OpenAI拉入了黑名单。3月份我国的百度也推出了和ChatGPT对标的文言一心,随后阿里也推出了自己的文本对话AI通义千问。这些都要花钱。如果你家里刚好有矿卡,也就是N卡,并且要求N卡的显存至少要6GB,那么你可以在本地电脑搭建类ChatGPT,也就是ChatGLM。都2023年了,我相信你的显存是够的。我电脑的显卡只有2GB,是不够的,但是我还是想要自己搭建一下来玩玩,于是我想到了可以租用云GPU。我知道的可以租用云GPU的提供商有国内的AutoDL,还有一个国外的Vultr。
我这里使用vultr作为演示,因为比较方便,但是价格好像要比国内的AutoDL要贵。我们也知道要用国内的服务器很蛮麻烦的,要实名制,要绑定微信,而使用vultr就很便利,直接注册,就能使用。
需要注意的是无论你是租用哪些供应商的GPU服务器,都要满足最低6GB显存的条件。
本次搭建的是清华大学开源的ChatGLM。源码地址。模型地址。
下面我通过vultr演示搭建过程。
环境:
- 系统:Ubuntu 22.04 LTS
- Python版本:高于python 3.7.1
- 显存:高于6GB
注意:不推荐使用CentOS系统,我刚开始就是使用CentOS 7系统,会遇到很多坑,比如Python版本的问题,因为CentOS是停止更新维护了的,并且官方vultr也不推荐使用CentOS系统。我推荐使用已经安装Anaconda环境的Ubuntu 22.04系统镜像。
1、服务器租用
你也可以在Windows电脑或者Mac电脑中搭建,我这里选择Linux,是因为我电脑的配置太低了,无法搭建。因为官方要求最低显存6GB,如果你本地电脑达到这个要求,那么你不用租用GPU服务器了,直接在本地电脑上搭建就行,并且把模型也下载到你本地电脑上,需要注意的是由于模型比较大,所以可能要占用你本地电脑的大量空间,不过现在电脑的空间普遍都比较大,不像我电脑只有512GB的空间。
点击这里进行GPU服务器的租用,注意,我们租用的是GPU服务,不是CPU服务器,我们知道一般服务器都是只有CPU的,但是如果你要做机器学习那么CPU就显得很吃力,我们要搭建ChatGLM也是要很大的算力,需要GPU。
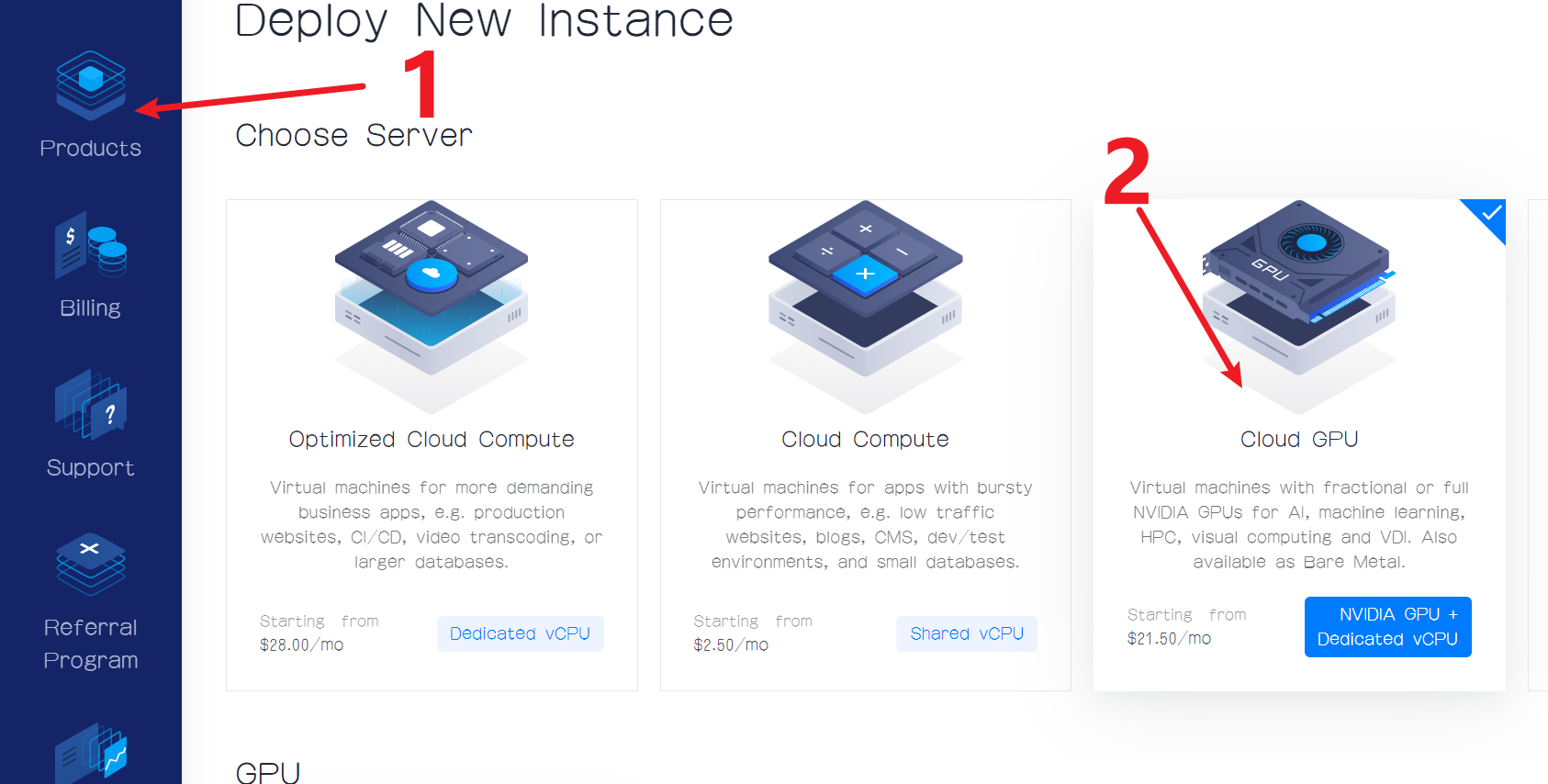
然后选GPU的类型,我们可以看到当前有三种可以选择,我这里选择A100。

然后是选择服务的位置,这里我选择New York。

然后是选择镜像或系统,这里我们不要选择CentOS系统。我选择安装了Anaconda的Ubuntu 22.04版本的镜像。
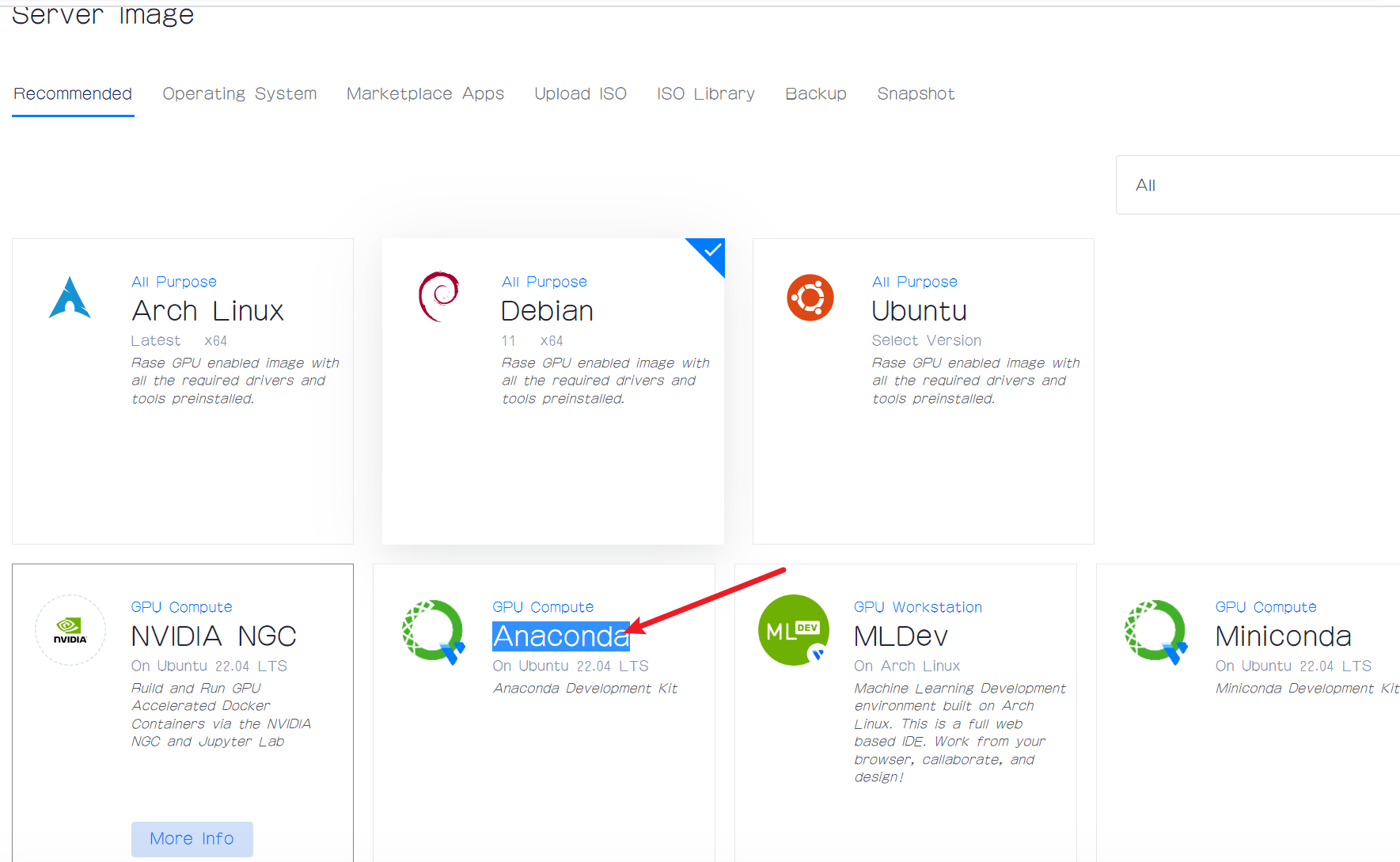
然后我们就可以选择显存的大小了,这里默认是选择第一个,也就是显存只有4GB,这是不够用的,我们选择第二个,也就是显存大小为8GB的服务器。
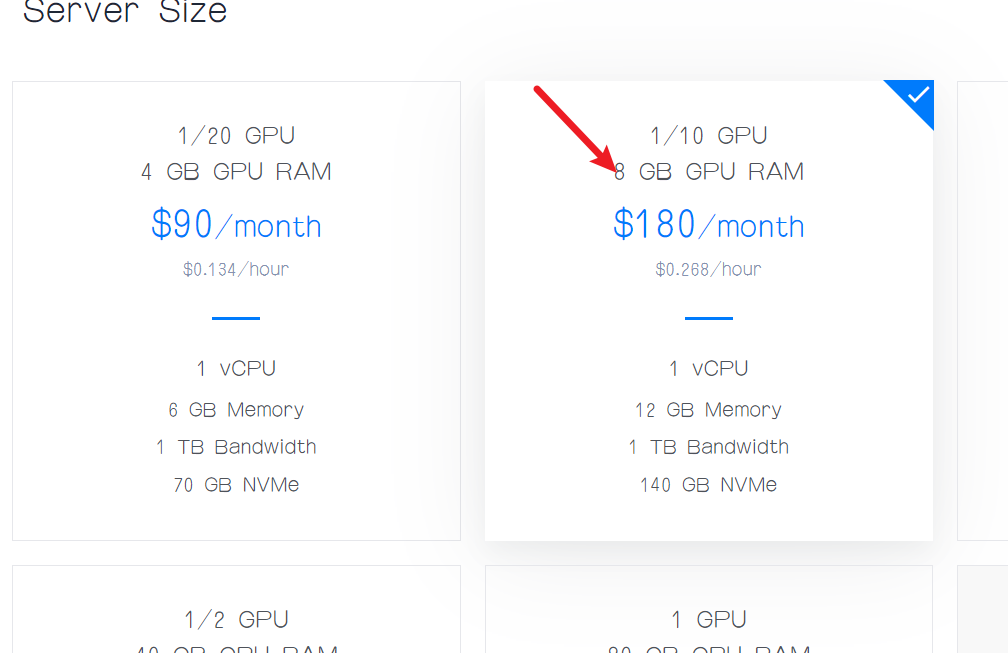
为了节省开支,这里推荐大家把Auto Backups关掉,因为这里需要收费的,并且费用还不便宜,比如我看到的这里是要收36美元一个月,你可以换算成人民币看看多少钱。
最后我们就可以点击Deploy Now了。

我们可以看到价格还是挺贵的,大概每小时大概1.85¥。自己玩一下还是可以的,是值得的,如果你觉得贵,你也可以去AutoDL中租用,AutoDL相对来说有更多可选择的空间,我目前看到最低是0.78¥/h。
注意:需要稍等几分钟,因为安装系统需要时间,等安装完成之后就可以使用了,并且默认是开启了22号端口的,我们可以直接使用SSH工具进行连接,这里我使用的是SecureCRT,当然你也可以使用其它的工具比如免费的PuTTY。
2、开启BBR加速
如何开启BBR加速可以去看我的这篇文章,Linux开启内核BBR加速。
3、拉取ChatGLM源码和ChatGLM模型
我这里在下载之前创建了一个目录专门存放ChatGLM相关的内容。
cd /opt
mkdir ChatGLM
cd ChatGLM
进入ChatGLM目录后,然后就可以下载ChatGLM源码了。
git clone https://github.com/lukeewin/ChatGLM-6B.git
然后我们还需要下载模型文件。并且模型比较大,所以在下载模型文件之前,我们还需要安装git-lfs。
apt install git-lfs
安装完全后,我们先创建一个目录专门存放模型文件,这里我在/opt/ChatGLM路径下创建一个目录。
mkdir model
cd model
然后我们就可以下下载模型数据了。
git lfs install
git clone https://huggingface.co/THUDM/chatglm-6b-int4
到这里,ChatGLM源码和对应的模型都克隆到服务器上了。
4、修改配置
在修改配置之前,我们还需要安装cuda。
apt install nvidia-cuda-toolkit
然后修改源码中的requirements.txt中的内容,在末尾添加下面三条语句。
chardet
streamlit
streamlit-chat
然后通过pip命令来安装相关的库。
pip install -r requirements.txt
然后,我们还要修改web_demo2.py文件。
修改下面两个地方,要使用绝对路径。

把上面这两个地方的值改为自己模型的路径,一定要使用绝对路径。
tokenizer = AutoTokenizer.from_pretrained("你自己模型的路径", trust_remote_code=True)
model = AutoModel.from_pretrained("你自己模型的路径", trust_remote_code=True).half().cuda()
然后我们开放一个端口作为web的对外访问端口。
ufw allow 8080/tcp
我这里开放的是8080端口。
你在开放前也可以使用下面的命令查看一下当前已经开放的端口。
ufw status
5、启动项目
python3 -m streamlit run ./web_demo2.py --server.port 8080
然后访问ip:8080就能够看到效果了。
6、效果
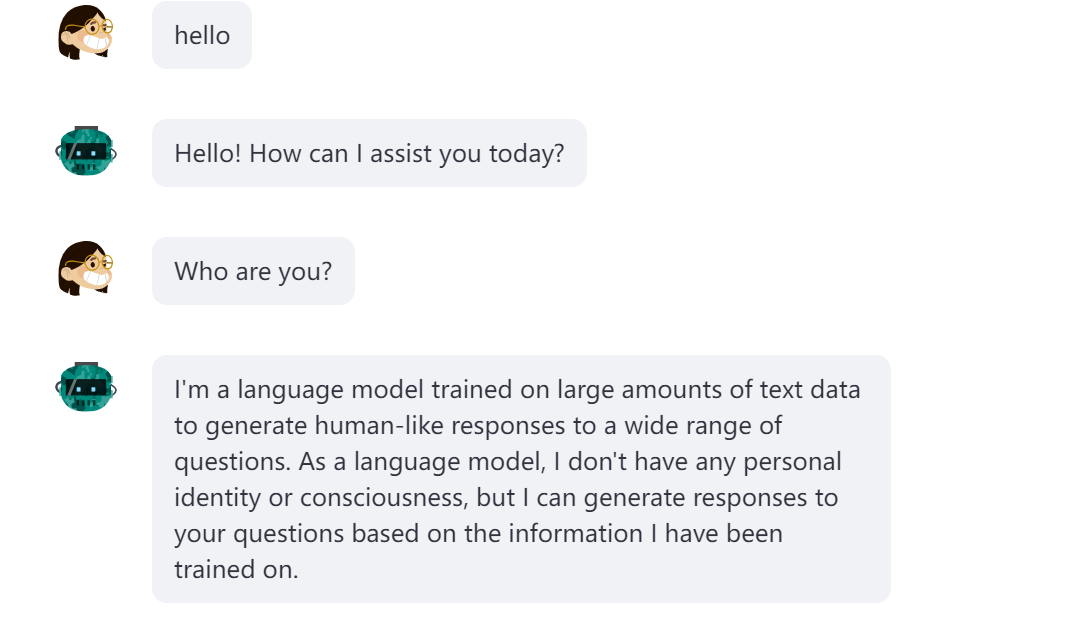
可以使用中文,也可以使用英语进行交流。
如果喜欢本篇文章,记得转发,点赞,收藏。
7、源码和模型下载
Q.E.D.

