SenseVoiceSmall区分说话人语音识别在通话录音转写中的优化 | FunASR区分说话人优化 ASR 这篇文章主要解决FunASR中使用SenseVoiceSmall模型在外呼系统中对通话录音转写识别区分说话人准确率的问题。文章讲述了如何提升FunASR区分说话人准确率,如何提高企业部署并发性问题。
部署kotoba_whisper文档 ASR 本地化部署开源的日语语音识别项目kotoba_whisper,可以区分说话人,可以返回时间戳,能精准识别日语,是基于whisper做的二次开发优化,专门针对日语进行语音转写的模型。这篇文档主要记录我当时部署中遇到的问题以及我是如何解决的,希望这篇文章对你有一定的帮助。
从零部署Fun-ASR-Nano实时语音识别并区分说话人教程 Linux 这篇文章主要讲述如何在Linux服务器中部署阿里开源的Fun-ASR项目,可以进行实时语音识别和区分说话人。主要记录了我是如何解决安装这些依赖以及其它系统环境的。使用了阿里开源的Fun-ASR-Nano-2512这个模型,进行流式实时语音转写同时可以输出单词级别的时间戳和区分说话人,可以应用到会议实时转写中,也可以应用到智能客户通话实时转写中。
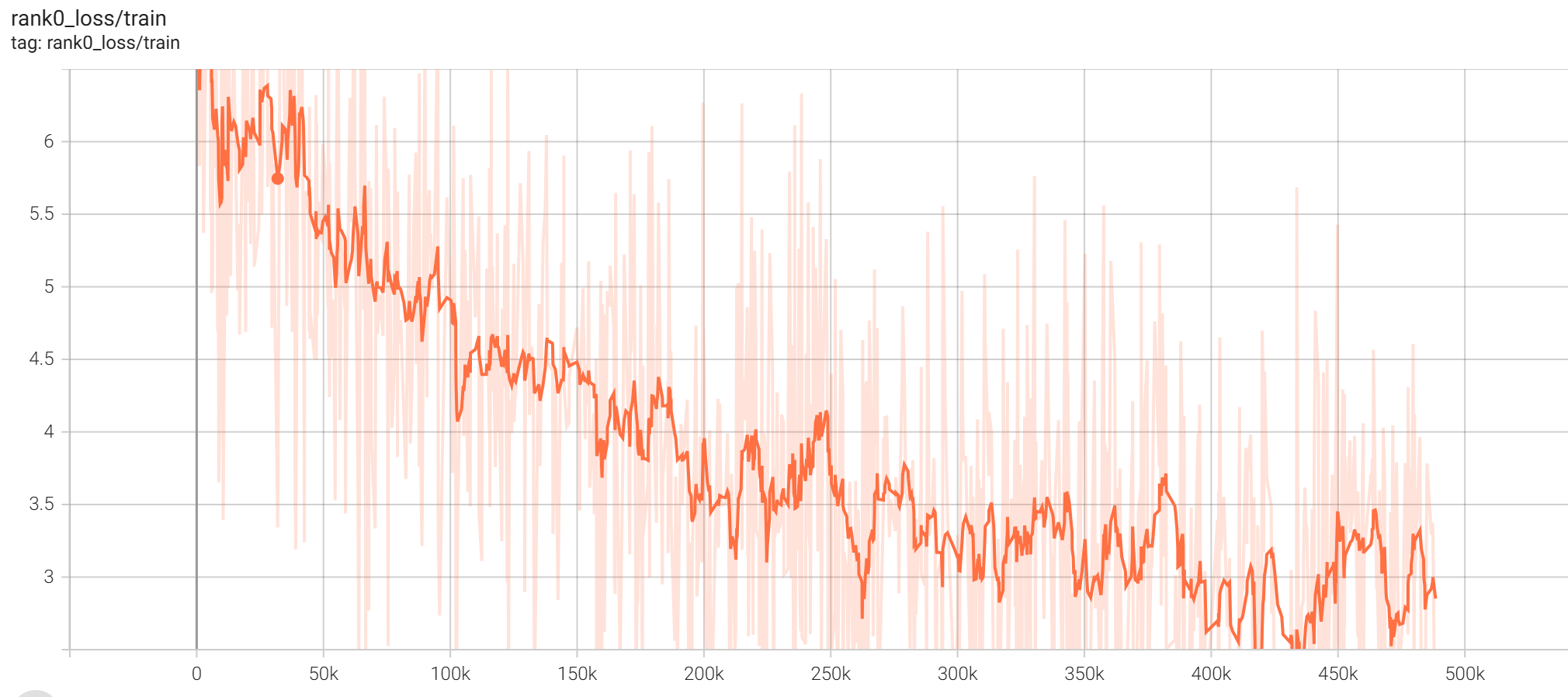
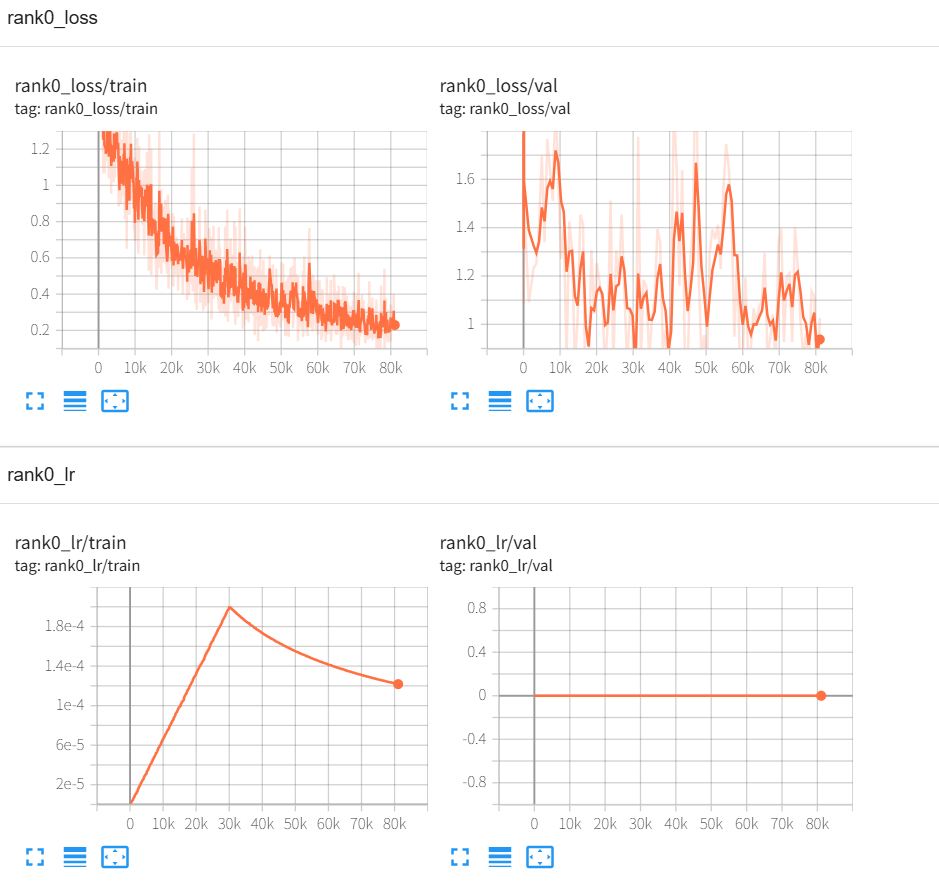
河南方言ASR模型训练最详细文章 ASR 河南方言ASR模型训练,基于阿里开源的SenseVoiceSmall训练可以准确识别河南方言的ASR模型,支持返回字级别时间戳,可以识别普通话和河南话,工业级水平的模型,适合应用在生产环境中,识别准确率是目前开源方言模型中识别河南方言最准确的模型之一。
部署Qwen3-ASR Linux 这篇文章主要讲述我是如何在Ubuntu服务器中本地化部署阿里最新开源的ASR大模型的,主要讲述如何部署Qwen3-ASR大模型,在服务器中本地化部署Qwen3-ASR大模型,以及解决vLLM部署Qwen3-ASR的问题。
Linux中部署GPT-OSS-20B大模型 | 服务器中部署OpenAI开源的大模型 | 私有化部署GPT-OSS-20B大模型 Linux 这篇文章主要讲述了我如何在Linux服务器中部署openai公司开源的生成式大模型gpt-oss-20b,以及这个部署过程中遇到的问题的解决方案。文章还讲述了如何在内网的环境中部署,并且解决了报错openai_harmony.HarmonyError的问题。
Linux中部署Qwen3.5大模型 | 本地私有化部署阿里最新开源Qwen3.5大模型 | 私有化部署本地大模型需要什么配置 Linux 这篇文章详细分享了如何在本地部署阿里最新开源的多模态大模型,支持图片识别,视频识别和文字生成。这篇文章记录我真实的部署过,在Linux服务器中部署开源的Qwen最新大模型。
ClearerVoice部署教程 | 基于AI的重叠语音分离 AI 这篇文章记录我如何在Linux中部署这个阿里开源的ClearerVoice的项目,这个ClearerVoice主要用于分离重叠说话人,目标说话人提取和降噪与人声增强。