









0. 研究背景
Fun-ASR-Nano-2512 是由阿里巴巴旗下的通义实验室开源的语音识别模型,通义实验室之前还开源了 SenseVoiceSmall 和 Paraformer 模型,这篇文章使用三种模型对多种方言,以及真实电话录音进行对比测试,在开源的数据集中评估的结果官方已经给出,这里使用自己的数据测试,不同的数据测试的字错率会不一样,这篇文章结果仅供大家参考,具体以你自己测试的结果为准。同时,还对比测试三种模型的转写速度以及转写时资源占用情况。
1. 推理代码
1.1 Fun-ASR-Nano 的推理代码
# !/usr/bin/env python
# _*_ coding utf-8 _*_
# @Time: 2025/12/15 20:18
# @Author: Luke Ewin
# @Blog: https://blog.lukeewin.top
from model import FunASRNano
import time
def main():
model_dir = "FunAudioLLM/Fun-ASR-Nano-2512"
start_model = time.time()
m, kwargs = FunASRNano.from_pretrained(model=model_dir, device="cuda")
end_model = time.time()
load_time_ms = (end_model - start_model) * 1000
print(f'加载模型Fun-ASR-Nano-2512耗时 {load_time_ms:.2f} 毫秒')
m.eval()
while True:
wav_path = input(f'输入音频路径')
if wav_path == 'exit':
break
start = time.time()
res = m.inference([wav_path], **kwargs)
end = time.time()
inference_time_ms = (end - start) * 1000
print(f'转写耗时:{inference_time_ms:.2f} 毫秒')
text = res[0][0]["text"]
print(text)
print(50*"-")
if __name__ == "__main__":
main()
1.2 SenseVoiceSmall 推理代码
# !/usr/bin/env python
# _*_ coding utf-8 _*_
# @Time: 2025/11/8 23:53
# @Author: Luke Ewin
# @Blog: https://blog.lukeewin.top
from funasr import AutoModel
from funasr.utils.postprocess_utils import rich_transcription_postprocess
import time
model_dir = "iic/SenseVoiceSmall"
start_model = time.time()
model = AutoModel(
model=model_dir,
device="cuda",
disable_update=True,
disable_log=True,
disable_pbar=True,
)
end_model = time.time()
load_time_ms = (end_model - start_model) * 1000
print(f'加载模型SenseVoiceSmall耗时 {load_time_ms:.2f} 毫秒')
while True:
audio = input("请输入要处理的音频:")
if audio == 'exit':
exit(0)
else:
start = time.time()
res = model.generate(
input=audio,
cache={},
language="auto",
use_itn=True,
batch_size_s=60,
)
end = time.time()
inference_time_ms = (end - start) * 1000
print(f'转写耗时:{inference_time_ms:.2f} 毫秒')
text = rich_transcription_postprocess(res[0]["text"])
print(text)
print(50*"-")
1.3 Paraformer 推理代码
这里使用的 Paraformer 是 seaco-paraformer
# !/usr/bin/env python
# _*_ coding utf-8 _*_
# @Time: 2025/12/10 21:51
# @Author: Luke Ewin
# @Blog: https://blog.lukeewin.top
from funasr import AutoModel
import time
start_model = time.time()
model = AutoModel(model="paraformer-zh", disable_update=True, disable_log=True, disable_pbar=True, device="cuda")
end_model = time.time()
load_time_ms = (end_model - start_model) * 1000
print(f'加载模型paraformer-zh耗时 {load_time_ms:.2f} 毫秒')
while True:
wav_path = input(f'输入音频路径')
if wav_path == 'exit':
exit(0)
start = time.time()
res = model.generate(input=wav_path, batch_size_s=300, hotword='魔搭')
end = time.time()
inference_time_ms = (end - start) * 1000
print(f'转写耗时:{inference_time_ms:.2f} 毫秒')
print(res)
print(50*"-")
2. 测试环境
| CPU | GPU | 内存 | 硬盘 |
|---|---|---|---|
| Intel® Xeon® Platinum 8470Q | NVIDIA RTX 5090 | 90GB | 80GB |
| 25内核 | 32GB显存 |
3. 方言识别测试
这里测试客家话,四川话,莆田话这三种方言的识别情况。
3.1 客家话
标注文本:
| 音频名 | 音频内容 | 音频时长 |
|---|---|---|
| hakka_a | 你好,大家好,欢饮大家来到我的视频频道 | 00:00:09.96 |
| hakka_b | 你吃饭了吗?今晚你吃什么菜呢? | 00:00:08.48 |
| hakka_test | 现在我来测试一下语音识别,看看识别的怎么样? | 00:00:08.66 |
paraformer 测试结果如下:
| 音频名 | 转写结果 | 转写耗时 | 显存占用 | 内存占用 |
|---|---|---|---|---|
| hakka_a | 你 以 后 太 敢 后 我 眼 太 敢 来 到 然 后 的 心 频 很 痛 | 1660.61 毫秒 | 1590MiB | 3GB |
| hakka_b | 女 sydlijama 你 said mila china | 124.12 毫秒 | 1590MiB | 3GB |
| hakka_test | 上 来 了 克 斯 汉 tae sept 怎 么 样 | 126.03 毫秒 | 1590MiB | 3GB |
可以看到转写的结果很不理想,全都是错误的。
SenseVoiceSmall 测试结果如下:
| 音频名 | 转写结果 | 转写耗时 | 显存占用 | 内存占用 |
|---|---|---|---|---|
| hakka_a | 如何太假呵稳人太假来到我的视频平托。 | 1050.31 毫秒 | 1578MiB | 1.2GB |
| hakka_b | 儿式花靓忙点呀儿式乜牙菜呢? | 62.43 毫秒 | 1578MiB | 1.2GB |
| hakka_test | 地下奶来测试一下二唔识劈替替食劈的怎么样。 | 61.10 毫秒 | 1578MiB | 1.2GB |
Fun-ASR-Nano 测试结果如下:
| 音频名 | 转写结果 | 转写耗时 | 显存占用 | 内存占用 |
|---|---|---|---|---|
| hakka_a | 而后,泰甲后,阮用泰甲来到了的视频频道。 | 872.05 毫秒 | 3886MiB | 3.3GB |
| hakka_b | 儿识巴厘木,竟也儿识抹牙菜呢。 | 361.80 毫秒 | 3886MiB | 3.3GB |
| hakka_test | 接下来来测试一下语音识别,睇睇识别得怎么样? | 319.23 毫秒 | 3886MiB | 3.3GB |
3.2 四川话
标注文本:
| 音频名 | 音频内容 | 音频时长 |
|---|---|---|
| sichuan_segment_017 | 不想搞它了甩在这儿洗了不开等它搁那哦 | 00:00:04.63 |
| sichuan_segment_032 | 你又不是找不到我找不到 | 00:00:03.20 |
| sichuan_segment_001 | 我认为我老爸是一个非常有主意的人为啥子这么说呢 | 00:00:04.97 |
| sichuan_segment_040 | 事情是这样子的我们这个厨房呢它属于农村厨房 | 00:00:03.33 |
| sichuan_segment_042 | 它就会飘到这个灶台上面为了防止这个灰尘呢 | 00:00:03.63 |
| sichuan_segment_079 | 我老爸的主意他还多得很他还想把我们这个厕所加猪圈拆了 | 00:00:04.60 |
Paraformer 测试结果如下:
| 音频名 | 转写结果 | 转写耗时 | 显存占用 | 内存占用 |
|---|---|---|---|---|
| sichuan_segment_017 | 想 搞 头 了 乖 着 了 洗 了 不 开 那 可 能 哦 | 1238.11 毫秒 | 1590MiB | 3GB |
| sichuan_segment_032 | 你 又 不 找 不 到 给 我 找 不 到 | 113.02 毫秒 | 1590MiB | 3GB |
| sichuan_segment_001 | 我 认 为 我 老 汉 儿 是 一 个 非 常 有 主 意 的 人 为 啥 子 这 么 说 嘞 | 104.00 毫秒 | 1590MiB | 3GB |
| sichuan_segment_040 | 之 前 是 这 样 子 的 我 们 这 个 厨 房 呢 它 属 于 农 村 厨 房 | 88.34 毫秒 | 1590MiB | 3GB |
| sichuan_segment_042 | 它 就 会 飘 到 那 个 灶 台 上 面 为 了 防 止 这 个 灰 尘 呢 | 92.38 毫秒 | 1590MiB | 3GB |
| sichuan_segment_079 | 老 汉 的 主 意 他 还 多 得 很 他 还 想 把 我 们 这 个 厕 所 加 猪 间 拆 了 | 107.24 毫秒 | 1590MiB | 3GB |
SenseVoiceSmall 测试结果如下:
| 音频名 | 转写结果 | 转写耗时 | 显存占用 | 内存占用 |
|---|---|---|---|---|
| sichuan_segment_017 | 洗了不开那可能哦。 | 1068.64 毫秒 | 1578MiB | 1.3GB |
| sichuan_segment_032 | 你又找不到我找不到。 | 49.76 毫秒 | 1578MiB | 1.3GB |
| sichuan_segment_001 | 我认为我老汉儿是一个非常有主意的人,为啥子这么说呢? | 50.26 毫秒 | 1578MiB | 1.3GB |
| sichuan_segment_040 | 之前是这样子的,我们这个厨房呢,它属于农村厨房。 | 46.75 毫秒 | 1578MiB | 1.3GB |
| sichuan_segment_042 | 它就会飘到那个灶台上面。为了防止这个灰尘呢。 | 61.86 毫秒 | 1578MiB | 1.3GB |
| sichuan_segment_079 | 老汉儿的主意他还多得很,他还想把我们这个厕所加租件拆了。 | 67.45 毫秒 | 1578MiB | 1.3GB |
Fun-ASR-Nano 测试结果如下:
| 音频名 | 转写结果 | 转写耗时 | 显存占用 | 内存占用 |
|---|---|---|---|---|
| sichuan_segment_017 | 想搞头啊,拐得了啊,洗了不开,那可能啊。 | 715.69 毫秒 | 3882MiB | 3.1GB |
| sichuan_segment_032 | 我又不找不到,我找不到。 | 201.04 毫秒 | 3882MiB | 3.1GB |
| sichuan_segment_001 | 我认为我老汉儿是一个非常有主意的人,为啥子这么说呢? | 373.36 毫秒 | 3882MiB | 3.1GB |
| sichuan_segment_040 | 事情是这样子的,我们这个厨房呢,它属于农村厨房。 | 368.32 毫秒 | 3882MiB | 3.1GB |
| sichuan_segment_042 | 它就会飘到那个灶台上面,为了防止这个灰尘呢。 | 349.89 毫秒 | 3882MiB | 3.1GB |
| sichuan_segment_079 | 我老汉儿的主意他还多得很,他还想把我们这个厕所加猪圈拆了。 | 477.61 毫秒 | 3882MiB | 3.1GB |
3.3 莆田话
标注:
| 音频名 | 音频内容 | 音频时长 |
|---|---|---|
| putian_xiao_2 | 上午好,你今天忙不忙呀? | 00:00:04.59 |
| putian_xiao_3 | 嗨,这么巧碰到你啦! | 00:00:04.65 |
Paraformer 转写结果如下:
| 音频名 | 转写结果 | 转写耗时 | 显存占用 | 内存占用 |
|---|---|---|---|---|
| putian_xiao_2 | 哦 吼 the 今 我 on 不 on 啊 | 1267.43 毫秒 | 1590MiB | 3GB |
| putian_xiao_3 | 哎 这 杂 叫 碰 到 的 | 99.52 毫秒 | 1590MiB | 3GB |
SenseVoiceSmall 转写结果如下:
| 音频名 | 转写结果 | 转写耗时 | 显存占用 | 内存占用 |
|---|---|---|---|---|
| putian_xiao_2 | 哦吼,汝今晚红毋旺啊。 | 1059.76 毫秒 | 1578MiB | 1.3GB |
| putian_xiao_3 | 唉,即系左只碰够嘟。 | 50.68 毫秒 | 1578MiB | 1.3GB |
Fun-ASR-Nano 转写结果如下:
| 音频名 | 转写结果 | 转写耗时 | 显存占用 | 内存占用 |
|---|---|---|---|---|
| putian_xiao_2 | 好好啊,汝今晚安毋安啊? | 597.70 毫秒 | 3880MiB | 3.1GB |
| putian_xiao_3 | 诶即作者有碰到著。 | 230.47 毫秒 | 3880MiB | 3.1GB |
4. 带噪音的录音转写测试
Paraformer 模型转写:
| 音频名 | 音频时长 | 标注文本 | 转写结果 | 转写耗时 | 显存占用 | 内存占用 |
|---|---|---|---|---|---|---|
| telephone_1 | 00:00:06.64 | 最近这块资金有需要了解咨询的吗?最近,最近,(后面我也听不清) | 您 这 块 最 近 有 需 要 了 解 事 情 的 吗 啊 最 近 最 近 是 有 需 要 你 不 是 那 个 哪 哪 边 的 嗯 | 1250.00 毫秒 | 1590MiB | 3GB |
| telephone_2 | 00:00:04.42 | 嗯,嗯,时间蛮长的,你平时有时间开票交税吗? | 啊 啊 是 这 样 蛮 长 的 嗯 平 时 有 开 票 交 税 吗 | 96.50 毫秒 | 1590MiB | 3GB |
| telephone_short | 00:00:20.10 | 你好,12306有什么可以帮您。欸,你好,我要咨询一下 | 你 好 幺 二 三 零 六 请 问 什 么 可 以 帮 您 哎 你 好 我 要 咨 询 下 | 196.79 毫秒 | 1590MiB | 3GB |
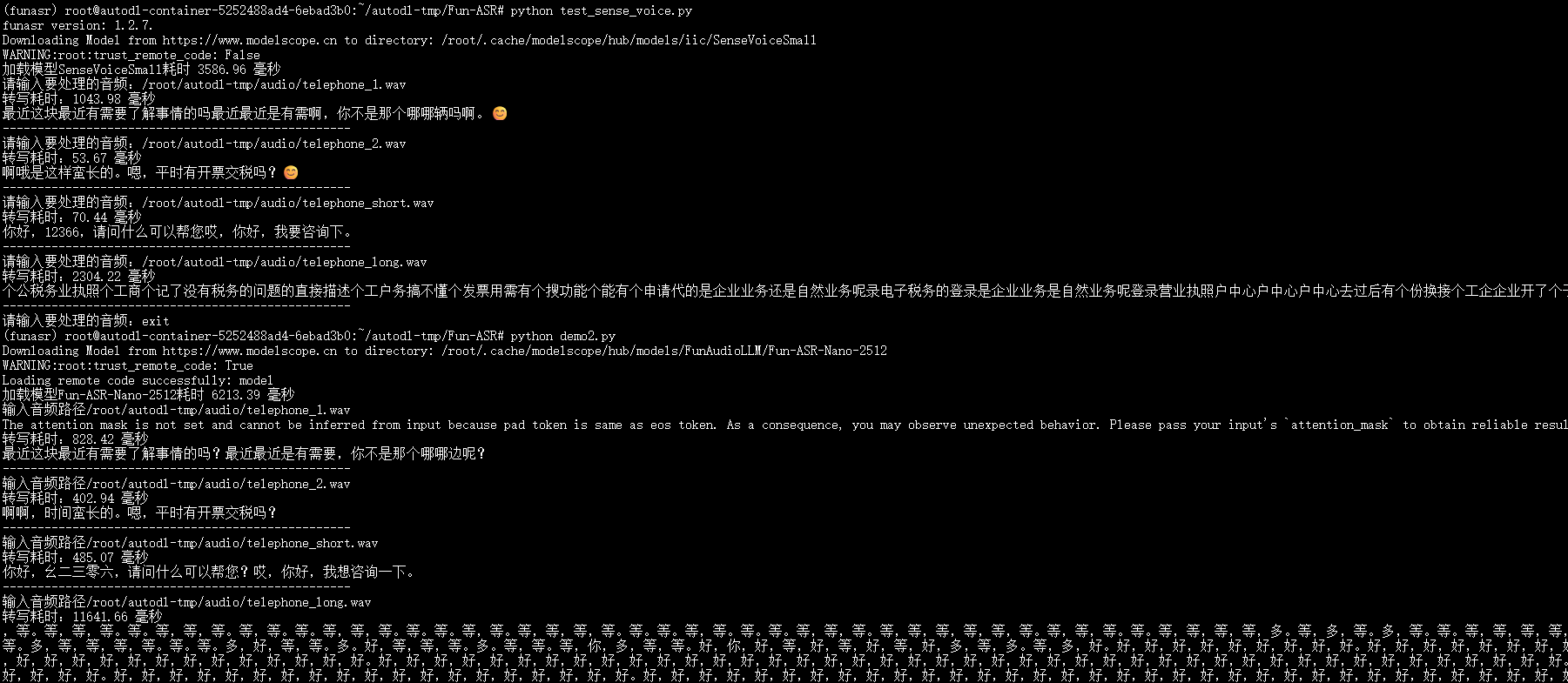
| telephone_long | 00:11:16.86 | … | 哦 对 登 话 是 企 个 企 业 营 户 证 不 我 我 我 我 办 办 办 在 企 业 业 户 营 办 户 户 户 不 我 我 我 话 现 在 企 办 的 账 话… | 5804.39 毫秒 | 1592MiB | 3GB |
SenseVoiceSmall 模型转写:
| 音频名 | 音频时长 | 标注文本 | 转写结果 | 转写耗时 | 显存占用 | 内存占用 |
|---|---|---|---|---|---|---|
| telephone_1 | 00:00:06.64 | 最近这块资金有需要了解咨询的吗?最近,最近,(后面我也听不清) | 最近这块最近有需要了解事情的吗最近最近是有需啊,你不是那个哪哪辆吗啊。😊 | 1043.98 毫秒 | 1578MiB | 1.2GB |
| telephone_2 | 00:00:04.42 | 嗯,嗯,时间蛮长的,你平时有时间开票交税吗? | 啊哦是这样蛮长的。嗯,平时有开票交税吗?😊 | 53.67 毫秒 | 1578MiB | 1.2GB |
| telephone_short | 00:00:20.10 | 你好,12306有什么可以帮您。欸,你好,我要咨询一下 | 你好,12366,请问什么可以帮您哎,你好,我要咨询下。 | 70.44 毫秒 | 1578MiB | 1.2GB |
| telephone_long | 00:11:16.86 | … | 个公税务业执照个工商个记了没有税务的问题的直接描述个工户务搞不懂个发票用需有个搜功能个能有个申请代的是企业业务还是自然业务呢录电子税务的登录是企业业务是自然业务呢登录营业执照户中心户中心户中心去过后有个份换接个工企企业开了个子。😊 | 2304.22 毫秒 | 1578MiB | 1.2GB |
Fun-ASR-Nano 模型转写:
| 音频名 | 音频时长 | 标注文本 | 转写结果 | 转写耗时 | 显存占用 | 内存占用 |
|---|---|---|---|---|---|---|
| telephone_1 | 00:00:06.64 | 最近这块资金有需要了解咨询的吗?最近,最近,(后面我也听不清) | 最近这块最近有需要了解事情的吗?最近最近是有需要,你不是那个哪哪边呢? | 828.42 毫秒 | 3894MiB | 3.1GB |
| telephone_2 | 00:00:04.42 | 嗯,嗯,时间蛮长的,你平时有时间开票交税吗? | 啊啊,时间蛮长的。嗯,平时有开票交税吗? | 402.94 毫秒 | 3894MiB | 3.1GB |
| telephone_short | 00:00:20.10 | 你好,12306有什么可以帮您。欸,你好,我要咨询一下 | 你好,幺二三零六,请问什么可以帮您?哎,你好,我想咨询一下。 | 485.07 毫秒 | 3894MiB | 3.1GB |
| telephone_long | 00:11:16.86 | … | ,等。等,等,等。等。等,等,等。等,等。等。等,等,等。等。等。等,等。等,等,等,等。等。等。等,等。等。等。等,等,等。等,等,等,等,等,等。等,等,等。等。等,等,等,等,多。等,多,等。多 | 11641.66 毫秒 | 27460MiB | 3.1GB |
这里发现一个问题,当输入长音频的时候,比如上面输入了11分钟多的音频,这个 Fun-ASR-Nano 的显存会涨很多,并且转写结束之后,不会恢复到之前的显存占用大小。并且这个输出的结果是完成不对的,如果使用的是 SenseVoiceSmall 则会进行截断,不会出现完全错误的结果,如果使用的 Paraformer 就会出现大量的重叠字。
5. 总结
| 准确率(由高到低排序) | 转写速度(由快到慢排序) | 资源占用(由多到少排序) |
|---|---|---|
| Fun-ASR-Nano | SenseVoiceSmall | Fun-ASR-Nano |
| SenseVoiceSmall | Fun-ASR-Nano | Paraformer |
| Paraformer | Paraformer | SenseVoiceSmall |
6. 其它
Paraformer、SenseVoiceSmall、Fun-ASR-Nano 深度对比测试演示视频可以点击这观看。
基于 205 小时四川话数据集训练的 Paraformer 模型,可点击这里获取。
基于 2231 条客家话数据集训练的 SenseVoiceSmall 模型,可点击这里获取。
Q.E.D.

