









1、创建虚拟环境
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh
sh Miniconda3-latest-Linux-x86_64.sh
source ~/.bashrc
conda create -n funasr python=3.7
conda activate funasr
2、安装依赖
pip3 install -U funasr -i https://mirror.sjtu.edu.cn/pypi/web/simple
pip3 install -U modelscope -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html -i https://mirror.sjtu.edu.cn/pypi/web/simple
pip3 install torch torchaudio
pip3 install onnx
pip3 install onnxruntime
python3 -m funasr.export.export_model \
--export-dir ./export \
--type onnx \
--quantize True \
--model-name damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch \
--model-name damo/speech_fsmn_vad_zh-cn-16k-common-pytorch \
--model-name damo/punc_ct-transformer_zh-cn-common-vocab272727-pytorch
3、下载onnxruntime
wget https://github.com/microsoft/onnxruntime/releases/download/v1.14.0/onnxruntime-linux-x64-1.14.0.tgz
tar -zxvf onnxruntime-linux-x64-1.14.0.tgz
4、安装系统依赖
sudo apt-get install libopenblas-dev #ubuntu
# sudo yum -y install openblas-devel #centos
apt-get install libssl-dev #ubuntu
# yum install openssl-devel #centos
5、编译安装
cd funasr/runtime/websocket
mkdir build && cd build
cmake -DCMAKE_BUILD_TYPE=release .. -DONNXRUNTIME_DIR=/path/to/onnxruntime-linux-x64-1.14.0 -DFFMPEG_DIR=/path/to/ffmpeg-N-111383-g20b8688092-linux64-gpl-shared
make
注意:/path/to/替换为真实路径。
6、运行
参考链接:https://github.com/lukeewin/FunASR/tree/main/funasr/runtime/websocket#service-with-websocket-cpp
./funasr-wss-server
--port 10096
--download-model-dir /workspace/models
--model-dir damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-onnx
--vad-dir damo/speech_fsmn_vad_zh-cn-16k-common-onnx
--punc-dir damo/punc_ct-transformer_zh-cn-common-vocab272727-onnx
--certfile ../../../ssl_key/server.crt
--keyfile ../../../ssl_key/server.key
--decoder-thread-num 16
--io-thread-num 16
如果要加载自己的模型,把--download-model-dir去掉,把--model-dir后面的值改为你模型的路径。
7、更换模型
从魔塔社区上下载模型。
转换为onnx
python -m funasr.export.export_model \
--model-name [model_name] \
--export-dir [export_dir] \
--type [onnx, torch] \
--quantize [true, false] \
--fallback-num [fallback_num]
python -m funasr.export.export_model
--model-name damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch
--export-dir ./export
--type onnx
--quantize True
参考文档:FunASR离线文件转写服务开发指南
8、支持时间戳
参考文档:https://github.com/alibaba-damo-academy/FunASR/discussions/246#discussioncomment-5449090
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
param_dict = dict()
param_dict['hotword'] = "hotword.txt"
inference_pipeline = pipeline(
task=Tasks.auto_speech_recognition,
model="damo/speech_paraformer-large-contextual_asr_nat-zh-cn-16k-common-vocab8404",
vad_model='damo/speech_fsmn_vad_zh-cn-16k-common-pytorch',
punc_model='damo/punc_ct-transformer_zh-cn-common-vocab272727-pytorch',
param_dict=param_dict)
inference_pipeline_tp = pipeline(
task=Tasks.speech_timestamp,
model='damo/speech_timestamp_prediction-v1-16k-offline',
output_dir='./tmp')
rec_result_asr = inference_pipeline(audio_in="test2.wav")
rec_result_tp = inference_pipeline_tp(audio_in="test2.wav",
text_in=" ".join(rec_result_asr['text']))
print(rec_result_asr, rec_result_tp)
效果:
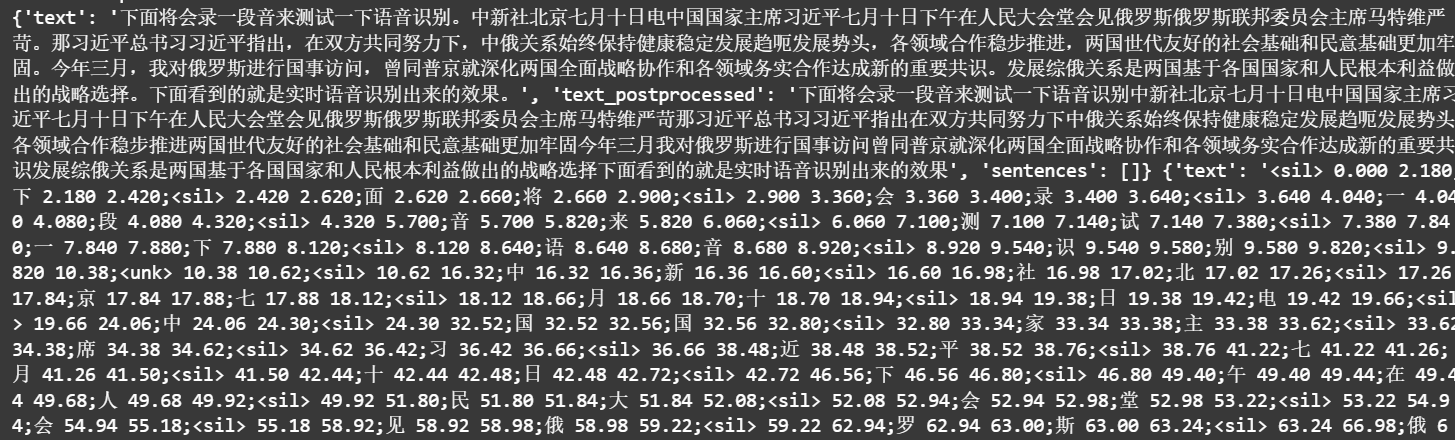
9、支持自定义热词
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
param_dict = dict()
param_dict['hotword'] = "resources/funasr/data/hotword.txt"
inference_pipeline = pipeline(
task=Tasks.auto_speech_recognition,
model="damo/speech_paraformer-large-contextual_asr_nat-zh-cn-16k-common-vocab8404",
vad_model='damo/speech_fsmn_vad_zh-cn-16k-common-pytorch',
punc_model='damo/punc_ct-transformer_zh-cn-common-vocab272727-pytorch',
param_dict=param_dict)
rec_result = inference_pipeline(audio_in='resources/funasr/audio/2.wav')
print(rec_result)
Q.E.D.

