









0. 说明
本次测试的是通过源码编译生成的可执行程序funasr-wss-server,不是通过拉取docker中的funasr-wss-server。官方有发布docker可拉取,但是镜像比较大,并且拉取速度慢,之前尝试拉取过几次,后面放弃了,转而使用源码编译方式生成可执行程序来测试。本次测试意在对比测试使用官方的GPU版本的FunASR和使用第三方的TensorRT来推理FunASR提供的模型的资源占用和转写速度,特别是在多卡情况下转写的速度。
测试数据集均为aishell1_test,总共10.03小时音频,7176条音频。
1. 测试环境
OS: Ubuntu 22.04
Python: 3.8
CUDA: 12.8
Pytorch:
RAM: 256GB
GPU: 8张魔改版2080Ti,每张22GB显存
CPU: Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz 56核心
2. 单卡测试
服务端启动参数:
--batch-size 32
--model-thread-num 16
--decoder-thread-num 16
--io-thread-num 8
| 并发数 | 耗时(单位秒) | GPU利用率 | CPU利用率 | RTF |
|---|---|---|---|---|
| 1 | 2769 | 6% | 300% | 0.0767 |
| 8 | 372 | 30% | 2000% | 0.0103 |
| 16 | 230 | 45% | 3000% | 0.0064 |
| 22 | 224 | 50% | 3000% | 0.0062 |
| 32 | 200 | 50% | 3300% | 0.0055 |
| 64 | 201 | 50% | 3300% | 0.0056 |
| 128 | 201 | 50% | 3300% | 0.0056 |
从上面测试结果来看,单张2080Ti魔改版显卡最大支持32并发,当并发数超过32后,RTF值没有明显变化。
同时得出一个结论,显卡利用率低,最多只能利用50%,相比于使用triton_gpu后端使用TensorRT来推理,利用率可以100%。
这里修改一下服务端参数,重新测试一下。
--batch-size 32
--model-thread-num 16
--decoder-thread-num 22
--io-thread-num 8
这里就不统计结果了,从实测来看,这个GPU利用率还是太低了,CPU利用率太高了。修改decoder-thread-num的值并没有提升GPU利用率。
3. 多卡测试
这里使用8张2080Ti显卡测试。
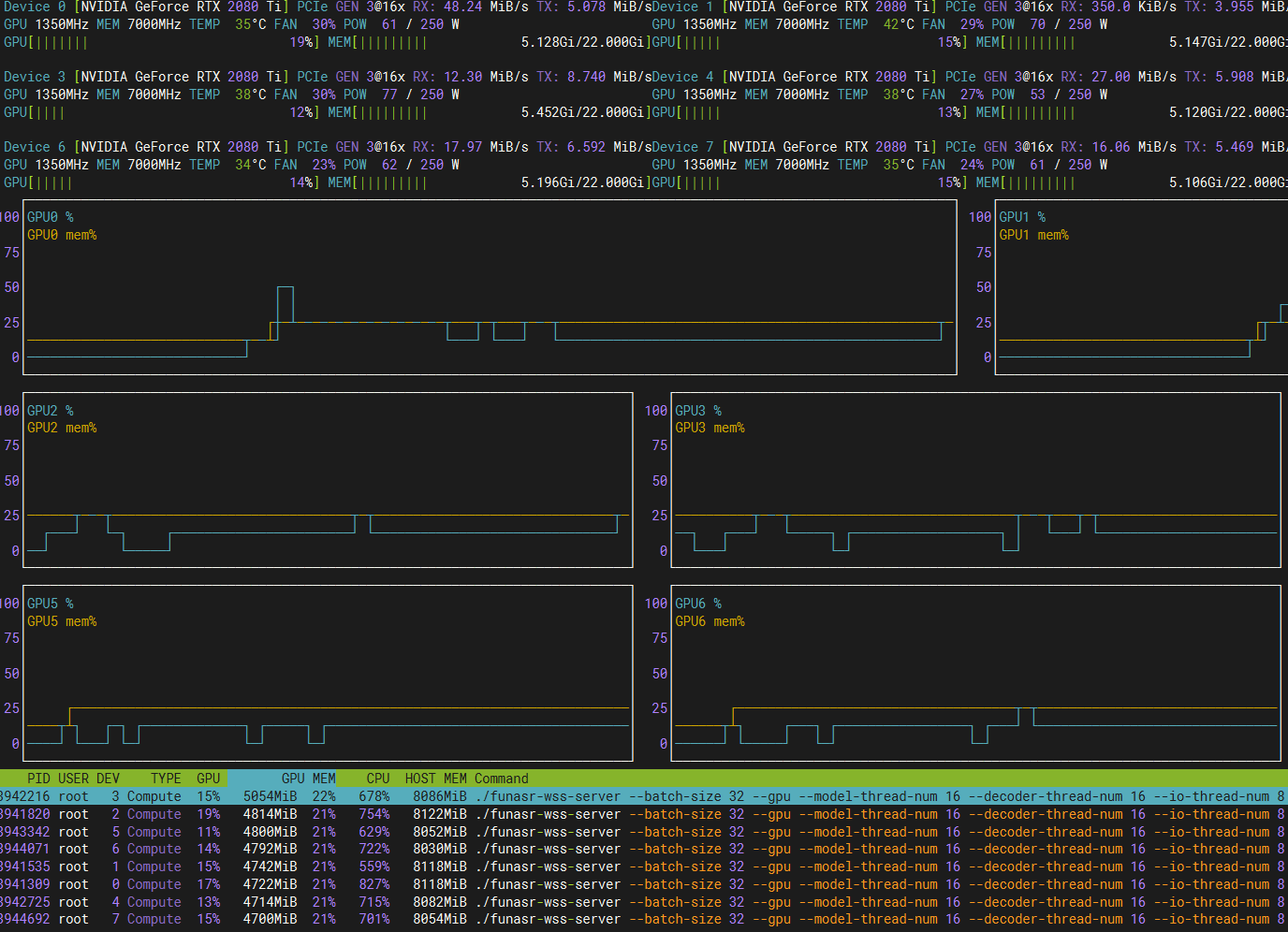
从上图中可以看出,在多显卡的情况下,显卡利用率更低,这里客户端是32路并发,有8个客户端,同时发送32的转写请求,也就是一共256路并发。

从上图可看出CPU已经成为了瓶颈,56个核心,全部100%。
Q.E.D.

