









0. 部署前的准备
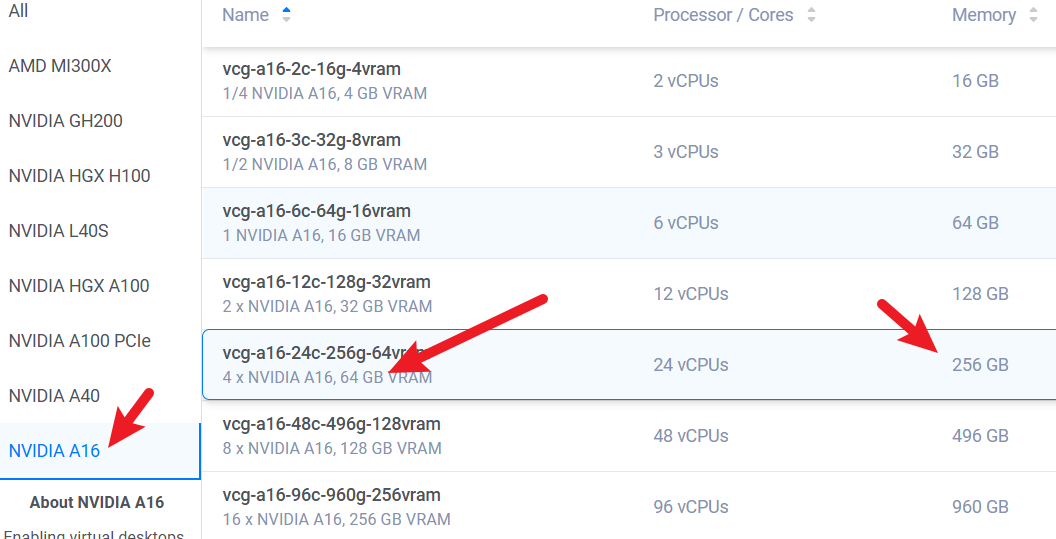
首先我们需要足够算力的机器,这里我在vultr中租了有一张A16显卡一共16GB显存的服务器作为演示。部署的模型参数为14b的。如果需要部署满血版本671b的,需要更大的算力支持,这里由于是个人资金有限,就演示14b的部署过程,671b的也一样的。如果你不懂,但是想要在本地或者服务器中部署,可以点击这里。
准备服务配置如下:点击可以访问
| 硬件 | 软件 |
|---|---|
| 1张英伟达A16显卡16GB显存 | Ubuntu22.04 |
| 24核心CPU | |
| 64GB运行内存 | |
| 350GB存储空间 |
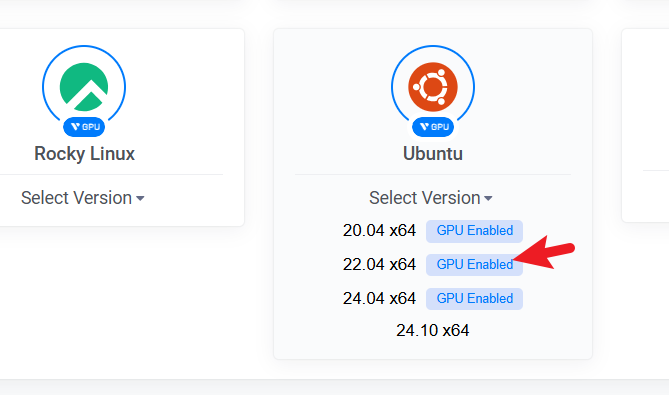
这里需要注意,在选择操作系统的时候,一定要选择支持GPU的操作系统,这里推荐使用Ubuntu。如下图所示。
如果不知道如何进入选择操作系统的页面,可以看我B站中的演示视频,搜索“编程分享录”用户名,进入空间后搜索“DeepSeek-R1服务器部署详细教程”。
1. 安装依赖
进入系统后,我们首先要执行下面命令。
apt-get update -y
apt-get upgrade -y
然后是安装ollama。点击这里访问ollama官方网站。执行下面sh脚本即可安装ollama
curl -fsSL https://ollama.com/install.sh | sh
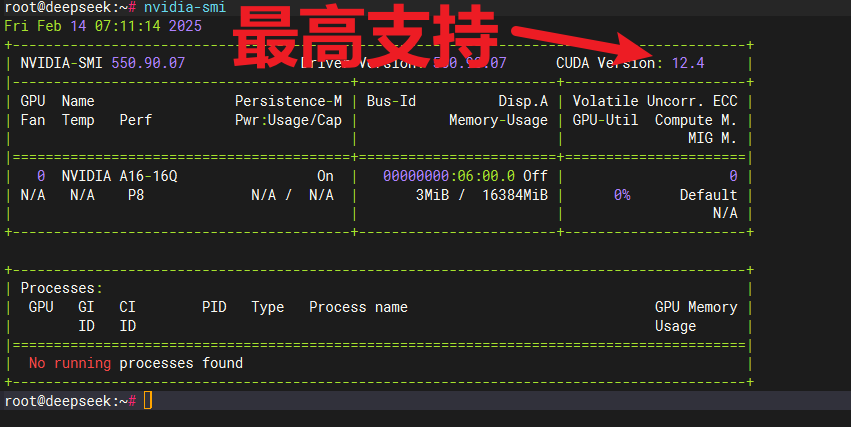
系统默认安装好了显卡驱动。
nvidia-smi
如下图所示:
 。
。
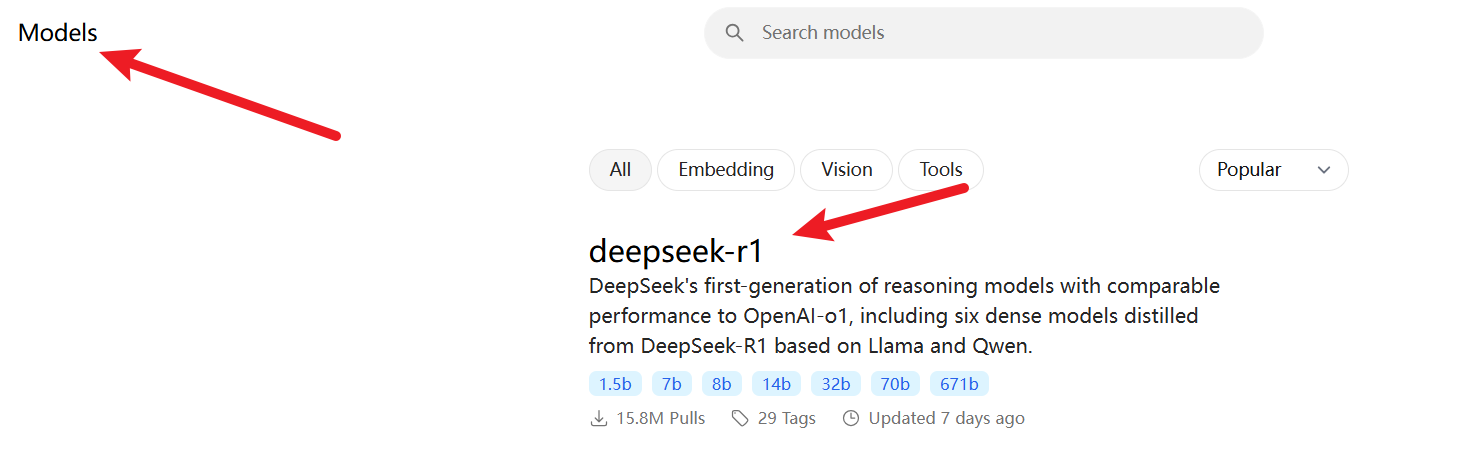
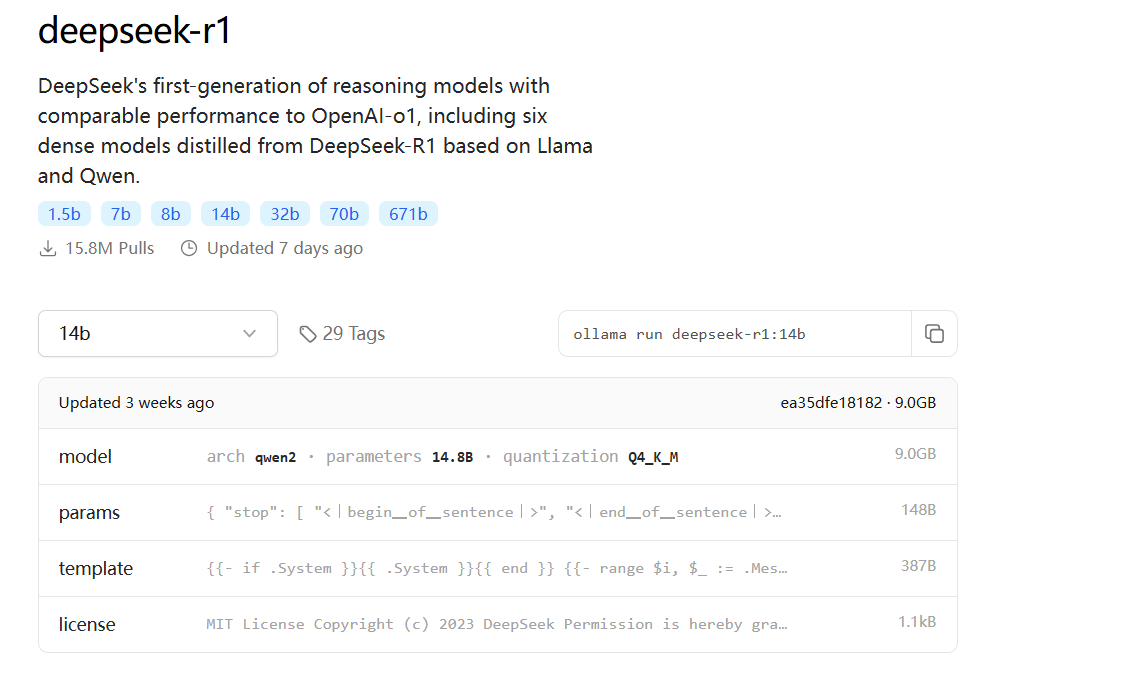
使用下面命令下载模型。
ollama run deepseek-r1:14b
那么现在我们就完成了服务器的部署,可以shell界面中进行问答,但是这样很不方便,我们可以借助chatbox的图形界面来对接我们部署的deepseek-r1大模型。
下载chatbox,可以点击这里,支持各种系统的客户端。不单电脑端可以用,手机(安卓和苹果)端也可以用。
下载完成后,直接双击安装就行。
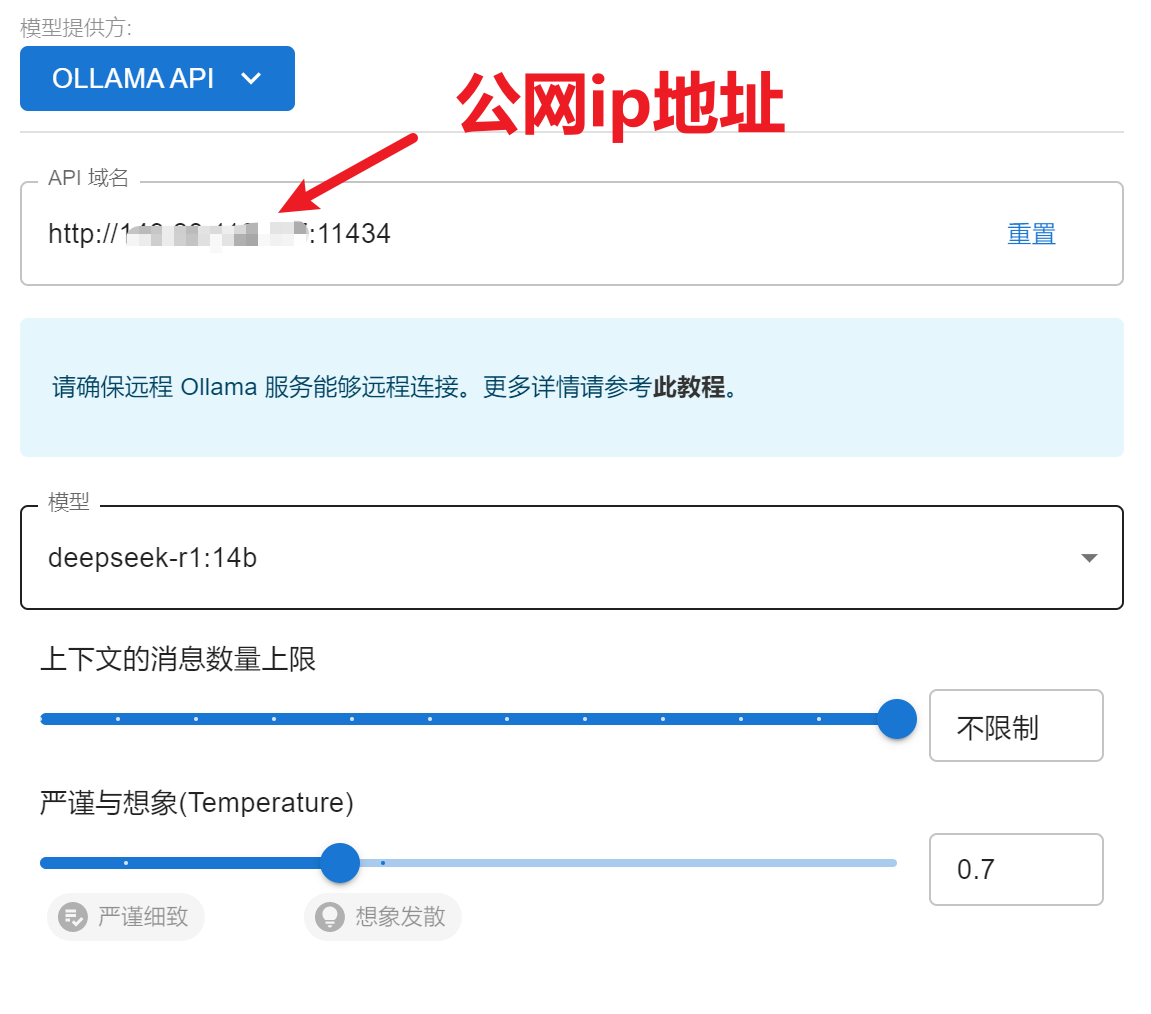
等待安装好之后,配置使用Ollama API方式对接deepseek大模型。
首先我们需要在服务器中安装ufw,然后开启11434端口。
apt-get install ufw
ufw allow 11434/tcp
然后修改Ollama配置文件。
vim /etc/systemd/system/ollama.service
添加下面内容。
Environment="OLLAMA_HOST=0.0.0.0"
Environment="OLLAMA_ORIGINS=*"
然后重新加载。
systemctl daemon-reload
systemctl restart ollama
然后就可以在本地电脑或者手机端配置chatbox了,如下图所示。
2. 测试
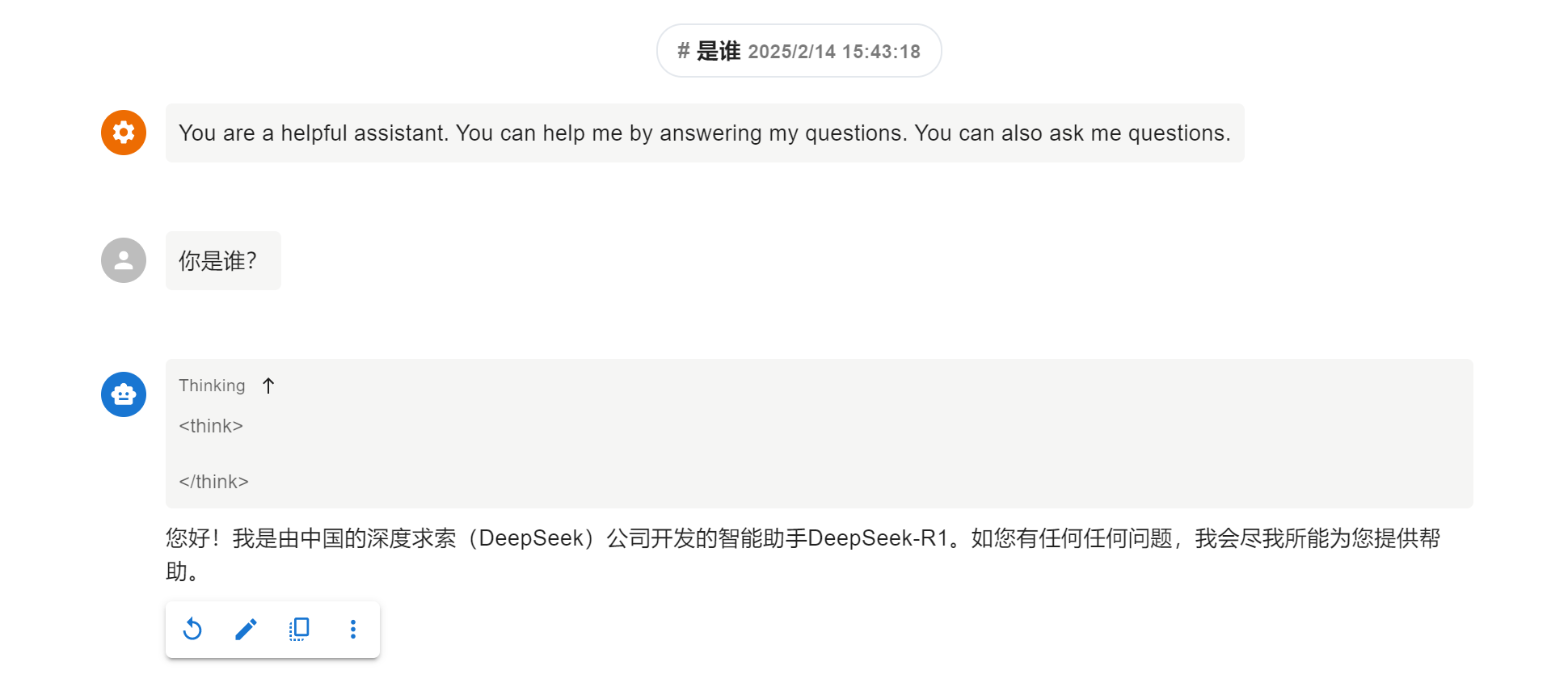
现在我们就部署完成了,可以在本地访问我们自己的大模型了。
Q.E.D.

