









1. 硬件
| CPU | GPU | 内存 |
|---|---|---|
| 10 vCPU Intel® Xeon® Gold 6248 CPU @ 2.50GHz | RTX 3080 Ti 12GB | 45GB |
2. 软件
| OS | Python | 后端推理引擎 |
|---|---|---|
| Ubuntu 22.04 | 3.12 | vLLM |
3. 部署
先安装uv。
curl -LsSf https://astral.sh/uv/install.sh | sh
这里部署的是Qwen3.5-2B模型,经过实测,跑4B模型显存溢出,只能跑2B参数量的模型。
uv venv qwen3.5
source qwen3.5/bin/activate
uv pip install vllm --torch-backend=auto --extra-index-url https://wheels.vllm.ai/nightly
uv pip install modelscope
4. 运行
VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3.5-2B --port 6006 --tensor-parallel-size 1 --max-model-len 128000 --reasoning-parser qwen3 --language-model-only
注意上面--language-model-only表示纯文本模式,这是多模态模型,这里只启动纯文本模式。
官方默认是--max-model-len 262144,这里修改为官方推荐最小值--max-model-len 128000。
5. 访问
接口遵循openai接口规范。
这里以python为客户端请求为例。
# !/usr/bin/env python
# _*_ coding utf-8 _*_
# @Time: 2026/3/23 1:53
# @Author: Luke Ewin
# @Blog: https://blog.lukeewin.top
import time
from openai import OpenAI
client = OpenAI(
api_key="EMPTY",
base_url="http://localhost:6006/v1",
timeout=3600
)
messages = [
{"role": "user", "content": "你给我讲一下睡前小故事吧"},
]
start = time.time()
response = client.chat.completions.create(
model="Qwen/Qwen3.5-2B",
messages=messages,
max_tokens=32768,
temperature=1.0,
top_p=1.0,
presence_penalty=2.0,
extra_body={
"top_k": 20,
"chat_template_kwargs": {"enable_thinking": False},
},
)
print(f"Response costs: {time.time() - start:.2f}s")
print(f"Generated text: {response.choices[0].message.content}")
6. 压测
经过实测发现这个Qwen3.5-2B占用显存将近12GB显存。
下面是压测命令。
vllm bench serve --backend openai-chat --endpoint /v1/chat/completions --model Qwen/Qwen3.5-2B --dataset-name random --random-input-len 2048 --random-output-len 512 --num-prompts 1000 --request-rate 20 --port 6006
压测结果如下:
============ Serving Benchmark Result ============
Successful requests: 1000
Failed requests: 0
Request rate configured (RPS): 20.00
Benchmark duration (s): 284.71
Total input tokens: 2048000
Total generated tokens: 512000
Request throughput (req/s): 3.51
Output token throughput (tok/s): 1798.33
Peak output token throughput (tok/s): 5627.00
Peak concurrent requests: 1000.00
Total token throughput (tok/s): 8991.65
---------------Time to First Token----------------
Mean TTFT (ms): 122682.20
Median TTFT (ms): 125387.52
P99 TTFT (ms): 226338.11
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 56.63
Median TPOT (ms): 58.24
P99 TPOT (ms): 78.05
---------------Inter-token Latency----------------
Mean ITL (ms): 56.66
Median ITL (ms): 22.26
P99 ITL (ms): 165.95
==================================================
从上面数据可以看出这张显卡跑这个模型并发不太高,每秒钟可以处理3路并发,如果需要每秒钟处理更高的并发,需要更换显存更大算力更强的显卡。
7. 补充
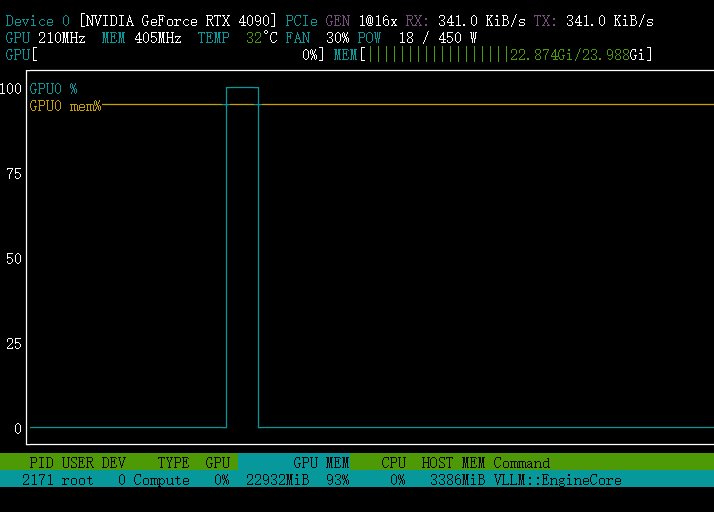
使用单张4090显卡跑Qwen3.5-4B模型,占用显存如下:
有偿部署可联系微信:lukeewin01
Q.E.D.

