









0. 说明
本文章记录自己训练MeloTTS模型的过程。

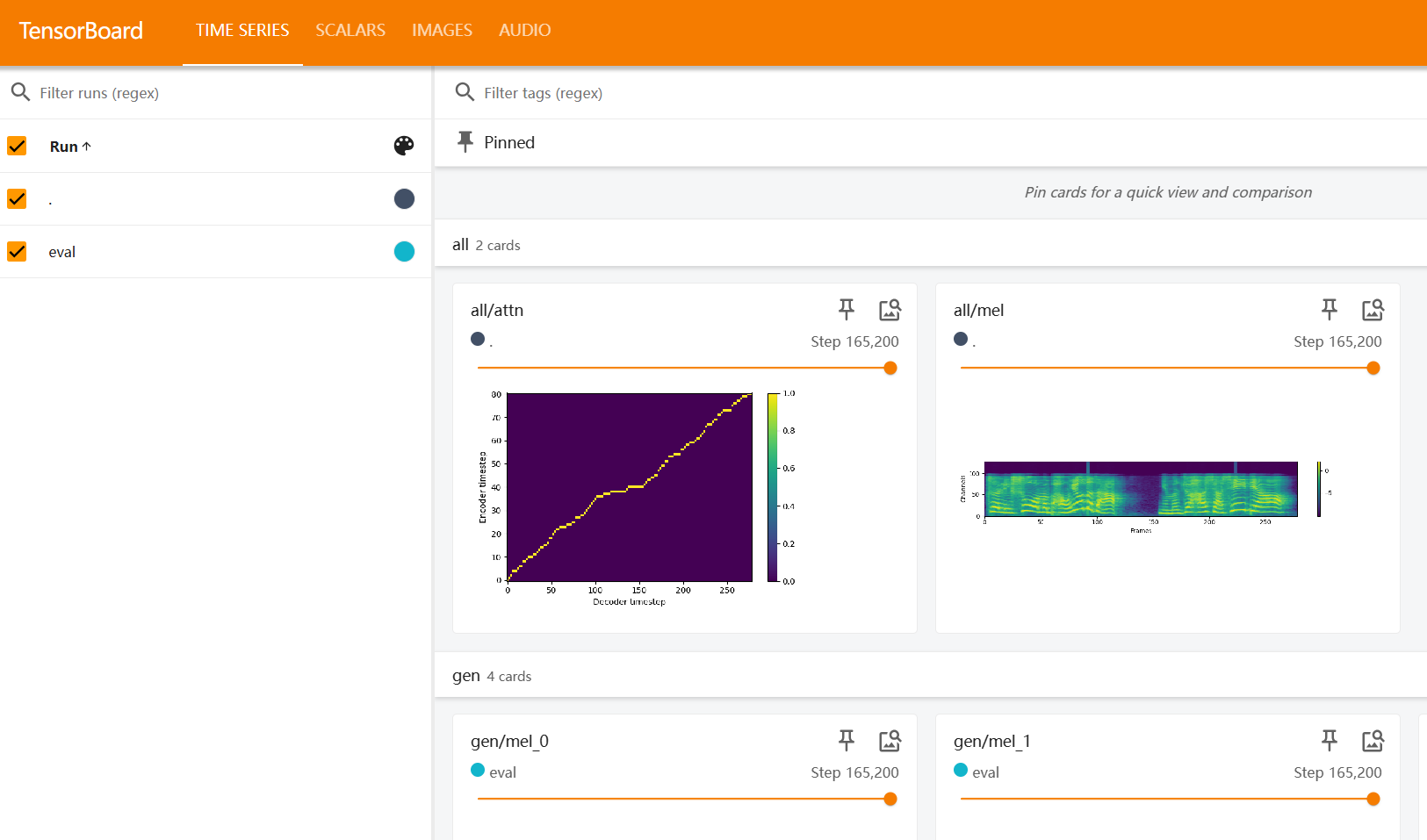
1. 数据准备
数据可以从huggingface或者modelscope中下载,国内的小伙伴可以在modelscope中下载模型更方便。
这里我使用huggingface中的中文语音合成数据集来训练,数据集id为xmj2002/genshin_ch_10npc
可以使用下面的命令来流式下载数据到服务器上。
import numpy as np
from scipy.io import wavfile
from datasets import load_dataset
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
mls = load_dataset("xmj2002/genshin_ch_10npc", split="train", streaming=True)
save_dir = "spk_pai"
os.makedirs(save_dir, exist_ok=True)
i = 0
for sample in mls:
if sample["npcName"] == "派蒙" and sample['language'] == 'CHS' and len(sample['text']) > 0:
print(sample)
# 获取音频数据
audio_array = sample["audio"]["array"]
# 将音频数据缩放到 -32768 到 32767 之间
audio_array = np.int16(audio_array / np.max(np.abs(audio_array)) * 32767)
# 保存音频数据
audio_path = os.path.join(save_dir, f"{i}.wav")
wavfile.write(audio_path, sample["audio"]["sampling_rate"], audio_array)
# 保存文本内容
text_path = os.path.join(save_dir, f"{i}.txt")
with open(text_path, "w", encoding="utf-8") as f:
f.write(sample["text"])
i += 1
在audio_array = np.int16(audio_array / np.max(np.abs(audio_array)) * 32767)这行中,主要是规定数据范围,如果没有这行,保存的音频会没有声音。
如果你使用的数据集不一样,那么你应该要改动上面代码。
上面代码主要目录是下载音频和对应的文本内容。
其中这里使用的声音是"派蒙",是一个游戏的人物角色声音。
2. 音频转码
这里推荐使用高保真率的音频,也就是44.1K的音频,并且要编码使用pcm_s16le的wav格式的单通道音频。如果你的训练数据音频不符合这些,那么就需要统一处理,进行音频转码。
import os
import ffmpeg
def process_convert_audio(input_path: str, output_path: str):
"""
音频转码 44.1k 1 pcm_s16le
@param input_path: 要转码的音频所在路径
@param output_path: 转码后的音频保存路径
@return:
"""
os.makedirs(output_path, exist_ok=True)
if os.path.exists(input_path) and os.path.isdir(input_path):
for root, dirs, files in os.walk(input_path):
for audio in files:
output_file_name = os.path.basename(audio)
input_file = os.path.join(root, audio)
output_file = os.path.join(output_path, output_file_name)
ffmpeg.input(input_file).output(output_file, ar=44100, ac=1, acodec='pcm_s16le').run()
如果你觉得数据集音频有较多的噪音,那么你也可以选择降噪和人声增强,可以安装https://github.com/resemble-ai/resemble-enhance.git。
安装命令:
pip install resemble-enhance --upgrade
然后就可以对指定的目录下的音频进行人声增强和降噪了。
resemble-enhance in_dir out_dir
并且支持并行处理,使用resemble-enhance -h可以查看到如何并行处理。
3. 训练环境安装
这里可以参考我之前写的文章,点击这里跳转到安装文章。
4. 标签处理
从这个数据集下载的标签中有些有特殊字符的需要通过python代码处理。
def process_label(label: str, output: str):
"""
处理文本内容,去掉特殊字符
@param label: 标签所在路径
@param output: 保存处理后的路径
@return:
"""
for root, dirs, files in os.walk(label):
for file in files:
label_file_path = os.path.join(root, file)
with open(label_file_path, 'r', encoding='utf-8') as f:
txt = f.read()
text = re.sub(r'<.*?>|「.*?」|\{.*?\}|#|\$UNRELEASED', '', txt)
output_file = os.path.join(output, file)
with open(output_file, 'w', encoding='utf-8') as out_f:
out_f.write(text)
out_f.flush()
处理完全之后要记得检查一下还有没有异常的内容,像+4这个"+"号也要去掉,否则会在生成config.json过程中报错误。
5. 生成metadata.list文件
格式要求:音频路径|speaker_id|language|音频对应的文本内容
def gen_metadata(audio_path: str, label_path: str, metadata_file: str):
"""
生成 metadata.list 文件
@param audio_path: 音频所在路径
@param label_path: 标签所在的路径
@param metadata_file: 保存生成后的 metadata.list 文件
@return:
"""
label_dict = {}
if os.path.exists(label_path) and os.path.isdir(label_path):
for root, dirs, files in os.walk(label_path):
for label in files:
label_name = os.path.basename(label).split('.txt')[0]
label_file_path = os.path.join(root, label)
with open(label_file_path, 'r', encoding='utf-8') as f:
txt = f.read()
label_dict[label_name] = txt
if os.path.exists(audio_path) and os.path.isdir(audio_path):
for root, dirs, files in os.walk(audio_path):
for audio in files:
audio_file_path = os.path.join(root, audio)
audio_name = os.path.basename(audio).split('.wav')[0]
if audio_name in label_dict:
label_txt = label_dict[audio_name]
if len(re.sub(r'[^\u4e00-\u9fff]', '', label_txt).strip()) != 0:
with open(metadata_file, 'a', encoding='utf-8') as f:
f.write(f'{audio_file_path}|lucy|EN|{label_txt}\n')
f.flush()
上面代码适用于一个目录下有音频和对应的每个标签的情况。
如果你下载的数据集是把全部的音频对应的标签存入一个文件中的情况,那么你需要自己写代码实现。
6. 生成config.json文件
使用下面命令来生成配置文件。
python preprocess_text.py --metadata data/example/metadata.list
把data/example/metadata.list改为自己的metadata.list文件路径。
运行上面的命令之后,会在metadata.list同级目录中生成几个文件,其中一个是config.json文件,我们需要打开这个文件,修改一些训练参数。
"train": {
"log_interval": 200,
"eval_interval": 1000,
"seed": 52,
"epochs": 10000,
"learning_rate": 0.0003,
"betas": [
0.8,
0.99
],
"eps": 1e-09,
"batch_size": 6,
"fp16_run": false,
"lr_decay": 0.999875,
"segment_size": 16384,
"init_lr_ratio": 1,
"warmup_epochs": 0,
"c_mel": 45,
"c_kl": 1.0,
"skip_optimizer": true
}
根据自己的数据集大小和显卡情况修改。这里我训练的数据集为10066条数据,显卡为单张RTX4090D显卡,所以我这里设置epochs=500,batch_size=16。
7. 开始训练
经过上面的准备工作,现在终于可以开始训练了。
首先我们需要修改一下官方给的训练脚本,修改为下面样子。
CONFIG=$1
GPUS=$2
MODEL_NAME=$(basename "$(dirname $CONFIG)")
PORT=10902
torchrun --nproc_per_node=$GPUS \
--master_port=$PORT \
train.py --c $CONFIG --model $MODEL_NAME
然后创建一个目录,把config.json文件复制进去。
mkdir model-zh-pai
这样做的目的是在训练启动的时候,会自动在源码中的melo/logs下面自动创建一个这样的目录,用于存放训练过程中的数据。
最后执行下面命令开始训练。
bash train.sh <path/to/config.json> <num_of_gpus>
上面这条命令中需要输入两个参数,一个是配置文件,一个是GPU数量,我这里只有一张显卡,所以最后一个参数是1。
8. 推理
使用下面命令进行推理。
python infer.py --text "<some text here>" -m /path/to/checkpoint/G_<iter>.pth -o <output_dir>
注意上面命令中并没有显示指定配置文件,其实代码内部会根据G_<iter>.pth所在的目录中查找配置文件。
如果想要在网页端使用,那么需要修改app.py代码。
models = {
'pai': TTS(language='ZH', device=device, config_path=r'C:\Users\21316\Downloads\MeloTTS-Train-Model-ZH-Pai\config.json', ckpt_path=r'C:\Users\21316\Downloads\MeloTTS-Train-Model-ZH-Pai\G_156400.pth'),
'EN': TTS(language='EN', device=device),
'ES': TTS(language='ES', device=device),
'FR': TTS(language='FR', device=device),
'ZH': TTS(language='ZH', device=device),
'JP': TTS(language='JP', device=device),
'KR': TTS(language='KR', device=device),
}
speaker_ids = models['EN'].hps.data.spk2id
default_text_dict = {
'pai': '我是派蒙,元神游戏中的一个人物,你听我的声音像吗?',
'EN': 'The field of text-to-speech has seen rapid development recently.',
'ES': 'El campo de la conversión de texto a voz ha experimentado un rápido desarrollo recientemente.',
'FR': 'Le domaine de la synthèse vocale a connu un développement rapide récemment',
'ZH': 'text-to-speech 领域近年来发展迅速',
'JP': 'テキスト読み上げの分野は最近急速な発展を遂げています',
'KR': '최근 텍스트 음성 변환 분야가 급속도로 발전하고 있습니다.',
}
def synthesize(speaker, text, speed, language, progress=gr.Progress()):
bio = io.BytesIO()
models[language].tts_to_file(text, models[language].hps.data.spk2id[speaker], bio, speed=speed, pbar=progress.tqdm, format='wav')
return bio.getvalue()
def load_speakers(language, text):
if text in list(default_text_dict.values()):
newtext = default_text_dict[language]
else:
newtext = text
return gr.update(value=list(models[language].hps.data.spk2id.keys())[0], choices=list(models[language].hps.data.spk2id.keys())), newtext
with gr.Blocks() as demo:
gr.Markdown('# MeloTTS WebUI\n\nA WebUI for MeloTTS.')
with gr.Group():
speaker = gr.Dropdown(speaker_ids.keys(), interactive=True, value='EN-US', label='Speaker')
language = gr.Radio(['pai', 'EN', 'ES', 'FR', 'ZH', 'JP', 'KR'], label='Language', value='EN')
speed = gr.Slider(label='Speed', minimum=0.1, maximum=10.0, value=1.0, interactive=True, step=0.1)
text = gr.Textbox(label="Text to speak", value=default_text_dict['EN'])
language.input(load_speakers, inputs=[language, text], outputs=[speaker, text])
btn = gr.Button('Synthesize', variant='primary')
aud = gr.Audio(interactive=False)
btn.click(synthesize, inputs=[speaker, text, speed, language], outputs=[aud])
gr.Markdown('WebUI by [mrfakename](https://twitter.com/realmrfakename).')
@click.command()
@click.option('--share', '-s', is_flag=True, show_default=True, default=False, help="Expose a publicly-accessible shared Gradio link usable by anyone with the link. Only share the link with people you trust.")
@click.option('--host', '-h', default=None)
@click.option('--port', '-p', type=int, default=None)
def main(share, host, port):
demo.queue(api_open=False).launch(show_api=False, share=share, server_name=host, server_port=port)
然后启动这个app.py就可以在网页端进行语音合成了。
那么到此,这篇文章就写完了。如果需要有偿训练模型,欢迎联系我,如果想要购买已经训练好的“派蒙”模型,也可以联系我。
视频教程。
Q.E.D.

