









1. 训练软硬件条件
1.1 硬件
| CPU | GPU | Memory |
|---|---|---|
| i7 14700KF 28核心 | RTX 3090Ti 24GB | 64GB |
1.2 软件
| OS | CUDA | Python | Torch |
|---|---|---|---|
| Ubuntu 24.04 | 12.8 | 3.10.16 | 2.7.0+cu128 |
2. 数据集准备
一共有500小时河南话和约100小时普通话,一共分为三个集合,训练集,验证集和测试集,其中训练集占比90%,验证集和测试集分别占比5%。
2.1 整理河南话数据集
这里采购的河南话数据集是pcm格式的音频,需要统一转码为wav格式,并且是单声道,16k采样率,位深为16bit的小端音频。可以使用下面的python代码统一转码处理。
# !/usr/bin/env python
# _*_ coding utf-8 _*_
# @Time: 2026/2/23 22:48
# @Author: Luke Ewin
# @Blog: https://blog.lukeewin.top
import os
import sys
import wave
def convert_pcm_to_wav(pcm_path, wav_path):
"""
将单个 PCM 文件转换为 WAV 文件。
参数:
pcm_path: 输入的 PCM 文件路径
wav_path: 输出的 WAV 文件路径
"""
try:
# 以二进制方式读取整个 PCM 数据
with open(pcm_path, 'rb') as f:
pcm_data = f.read()
# 创建并写入 WAV 文件
with wave.open(wav_path, 'wb') as wav_file:
wav_file.setnchannels(1) # 单声道
wav_file.setsampwidth(2) # 16 位 = 2 字节
wav_file.setframerate(16000) # 采样率 16kHz
wav_file.writeframes(pcm_data)
print(f"转换成功: {pcm_path} -> {wav_path}")
return True
except Exception as e:
print(f"转换失败 {pcm_path}: {e}", file=sys.stderr)
return False
def process_directory(root_dir, output_wav_dir):
"""
遍历目录及其子目录,找到所有 .pcm 文件并转换。
"""
for dirpath, _, filenames in os.walk(root_dir):
for filename in filenames:
if filename.lower().endswith('.pcm'):
pcm_full = os.path.join(dirpath, filename)
filename_noext = os.path.splitext(filename)[0]
wav_full = os.path.join(output_wav_dir, filename_noext + '.wav')
convert_pcm_to_wav(pcm_full, wav_full)
def main():
root_dir = input("请输入要处理的pcm文件路径")
output_wav_dir = input("请输入要输出的wav文件路径")
if not os.path.isdir(root_dir) or not os.path.isdir(output_wav_dir):
print(f"错误:'{root_dir}或{output_wav_dir}' 不是有效的目录。")
sys.exit(1)
process_directory(root_dir, output_wav_dir)
if __name__ == '__main__':
main()
同时采购的这个河南话数据集中标注文档也需要处理为FunASR要求的格式,采购的数据集提供的是一个.scp文件,内容结构如下:
99000010001.pcm 废话 老王那么潇洒
99000010002.pcm 等下你不是要去发货吗
99000010003.pcm 你们是不是只是网店
99000010004.pcm 不过不严重 没啥事
99000010005.pcm 明天上班儿 你来上班儿
99000010006.pcm 没人在家都上学咧
99000010007.pcm 我看咱俩儿挺近的离的
99000010008.pcm 我以为你用电脑上的嘞
从上面的scp文件中可以看到,对方是把标点符号替换为空格了,这里需要把这些内容中多余的空格去掉。可以使用vscode工具,先把".pcm “替换为“|”,然后替换掉全部的空格,这种方式最快捷。当然你也可以编写python脚本来处理。这里为了快速方便,就直接使用vscode进行替换,把空格替换为空(这里指的是没有任何内容,包括空格也不要输入),最后还要记得把”.pcm "给替换回来。
2.2 整理普通话数据集
为了使得训练后的模型既可以识别河南方言,也可以识别普通话,这里加入了大约100小时的普通话一起训练,这个普通话数据集,我是从huggingface中下载的,如何下载可以使用下面的python代码。
# !/usr/bin/env python
# _*_ coding utf-8 _*_
# @Time: 2026/4/10 17:57
# @Author: Luke Ewin
# @Blog: https://blog.lukeewin.top
"""
从 huggingface 中下载 parquet 格式的数据集
"""
import os
os.environ["HTTP_PROXY"] = "http://127.0.0.1:10809"
os.environ["HTTPS_PROXY"] = "http://127.0.0.1:10809"
from datasets import load_dataset
dataset = load_dataset("urarik/free_st_chinese_mandarin_corpus", cache_dir=r"E:\Datasets\Mandarin")
print(dataset)
需要注意:这里使用了代理,如果你没有代理,可以使用huggingface的国内镜像,但是我电脑上试过,不太稳定,下载中途会中断,所以使用了代理。
下载好的是列存储的数据,也就是你在huggingface中看到的后缀为parquet的文件。那可以使用下面的python代码将数据提取出来,保存为16k单声道pcm_s16le的wav格式的音频和对应的funasr框架要求的scp和txt文件。
# !/usr/bin/env python
# _*_ coding utf-8 _*_
# @Time: 2026/4/10 23:35
# @Author: Luke Ewin
# @Blog: https://blog.lukeewin.top
import os
os.environ["HTTP_PROXY"] = "http://127.0.0.1:10809"
os.environ["HTTPS_PROXY"] = "http://127.0.0.1:10809"
from datasets import load_dataset
import soundfile as sf
from tqdm import tqdm
# ======================
# 1. 配置路径
# ======================
output_dir = r"E:\Datasets\Mandarin\funasr_format"
wav_dir = os.path.join(output_dir, "wav")
os.makedirs(wav_dir, exist_ok=True)
wav_scp_path = os.path.join(output_dir, "wav.scp")
text_path = os.path.join(output_dir, "text")
# ======================
# 2. 加载数据集
# ======================
dataset = load_dataset(
"urarik/free_st_chinese_mandarin_corpus",
cache_dir=r"E:\Datasets\Mandarin"
)
train_set = dataset["train"]
# ======================
# 3. 写文件
# ======================
with open(wav_scp_path, "w", encoding="utf-8") as f_wav, \
open(text_path, "w", encoding="utf-8") as f_txt:
for i, sample in enumerate(tqdm(train_set)):
utt_id = f"utt_{i:08d}"
audio = sample["audio"]
text = sample["sentence"].strip()
# 跳过空文本
if not text:
continue
wav_path = os.path.join(wav_dir, f"{utt_id}.wav")
# ======================
# 4. 保存音频
# ======================
sf.write(
wav_path,
audio["array"],
audio["sampling_rate"]
)
# ======================
# 5. 写scp和text
# ======================
f_wav.write(f"{utt_id} {wav_path}\n")
f_txt.write(f"{utt_id} {text}\n")
print("数据导出完成!")
print(f"wav.scp: {wav_scp_path}")
print(f"text: {text_path}")
注意:cache_dir的值填写你自己下载保存这个数据集的绝对路径。
2.3 打乱数据
把河南话数据和普通话数据放到一起,然后使用下面的python脚本打乱数据,并且分为三个集合,训练集,验证集和测试集,其中训练集占90%,验证集和测试集各占5%。
#!/usr/bin/env python3
"""
打乱并分割 scp 和 text 文件(保持行对应)
使用示例:
python shuffle_split.py wav.scp text.txt --output_dir ./data
"""
import argparse
import random
import os
from pathlib import Path
def read_lines(file_path):
"""读取文件所有行,去除末尾换行符"""
with open(file_path, 'r', encoding='utf-8') as f:
return [line.rstrip('\n') for line in f]
def write_lines(file_path, lines):
"""将列表写入文件,每行加换行符"""
with open(file_path, 'w', encoding='utf-8') as f:
for line in lines:
f.write(line + '\n')
def main():
parser = argparse.ArgumentParser(description="打乱并分割 scp 和 text 文件(保持对应)")
parser.add_argument("scp_file", type=str, help="输入的 .scp 文件路径")
parser.add_argument("txt_file", type=str, help="输入的 .txt 文件路径")
parser.add_argument("--output_dir", type=str, default=".", help="输出目录(默认为当前目录)")
parser.add_argument("--seed", type=int, default=42, help="随机种子(默认42)")
args = parser.parse_args()
# 设置随机种子保证可复现
random.seed(args.seed)
# 读取两个文件
scp_lines = read_lines(args.scp_file)
txt_lines = read_lines(args.txt_file)
# 检查行数是否一致
if len(scp_lines) != len(txt_lines):
raise ValueError(f"文件行数不一致: scp={len(scp_lines)}, txt={len(txt_lines)}")
total = len(scp_lines)
print(f"总行数: {total}")
# 将对应行打包并打乱
paired = list(zip(scp_lines, txt_lines))
random.shuffle(paired)
# 计算划分点(90% train, 5% vad, 5% test)
train_end = int(total * 0.9)
vad_end = train_end + int(total * 0.05)
# 剩余自动归为 test(可能因为取整有1条误差,test取剩余全部)
train_pairs = paired[:train_end]
vad_pairs = paired[train_end:vad_end]
test_pairs = paired[vad_end:]
print(f"划分情况: train={len(train_pairs)}, vad={len(vad_pairs)}, test={len(test_pairs)}")
# 创建输出目录(如果不存在)
out_dir = Path(args.output_dir)
out_dir.mkdir(parents=True, exist_ok=True)
# 解包并写入对应文件
for name, pairs in [("train", train_pairs), ("vad", vad_pairs), ("test", test_pairs)]:
scp_out = out_dir / f"{name}_wav.scp"
txt_out = out_dir / f"{name}_text.txt"
scp_content = [p[0] for p in pairs]
txt_content = [p[1] for p in pairs]
write_lines(scp_out, scp_content)
write_lines(txt_out, txt_content)
print(f"已生成: {scp_out} 和 {txt_out}")
if __name__ == "__main__":
main()
生成language, emo和event
def generate(text_file: str, save: str, type: str):
"""
根据输入的 train_text.txt 文件生成 train_text_language.txt train_emo.txt train_event.txt
:param text_file: 输入的 train_text.txt
:param save: 保存文件
:param type: 类型
:return:
"""
with open(text_file, 'r', encoding='utf-8') as r:
lines = r.readlines()
with open(save, 'w', encoding='utf-8') as w:
for line in lines:
tmp = line.strip().split(' ', 1)
uuid = tmp[0]
content = tmp[-1]
if content is not None:
w.write(f"{uuid} {type}\n")
text_file = r"D:\Works\Datasets\sichuan_datasets\sichuan.txt"
save = r"D:\Works\Datasets\sichuan_datasets\train_text_language.txt"
save_type = "<|zh|>"
generate(text_file, save, save_type)
注意需要将上面代码中的text_file和save替换为你自己的路径
2.4 生成训练所需的jsonl文件
使用下面的命令生成jsonl文件
生成train.jsonl文件
sensevoice2jsonl \
++scp_file_list='["/data/funasr/train_data/henan/label/train_wav.scp", "/data/funasr/train_data/henan/label/train_text.txt", "/data/funasr/train_data/henan/label/train_text_language.txt", "/data/funasr/train_data/henan/label/train_emo.txt", "/data/funasr/train_data/henan/label/train_event.txt"]' \
++data_type_list='["source", "target", "text_language", "emo_target", "event_target"]' \
++jsonl_file_out="/data/funasr/train_data/henan/label/train.jsonl"
生成val.jsonl文件
sensevoice2jsonl \
++scp_file_list='["/data/funasr/train_data/henan/label/val_wav.scp", "/data/funasr/train_data/henan/label/val_text.txt", "/data/funasr/train_data/henan/label/val_text_language.txt", "/data/funasr/train_data/henan/label/val_emo.txt", "/data/funasr/train_data/henan/label/val_event.txt"]' \
++data_type_list='["source", "target", "text_language", "emo_target", "event_target"]' \
++jsonl_file_out="/data/funasr/train_data/henan/label/val.jsonl"
生成train.jsonl过程截图如下:
3. 开始训练
经过放上面的数据集准备,也就是现在已经有了train.jsonl和val.jsonl两个文件,我们就可以开始训练了。首先需要修改finetune.sh,如下:
# 要记得修改为自己上面生成的那两个jsonl所在的绝对路径
train_data=/data/funasr/train_data/henan/label/train.jsonl
val_data=/data/funasr/train_data/henan/label/val.jsonl
# 这个是保存训练后的模型文件路径
output_dir="/data/funasr/train_data/henan/trained"
log_file="${output_dir}/log.txt"
torchrun $DISTRIBUTED_ARGS \
${train_tool} \
++model="${model_name_or_model_dir}" \
++train_data_set_list="${train_data}" \
++valid_data_set_list="${val_data}" \
++dataset_conf.data_split_num=1 \
++dataset_conf.batch_sampler="BatchSampler" \
++dataset_conf.batch_size=20000 \
++dataset_conf.sort_size=1024 \
++dataset_conf.batch_type="token" \
++dataset_conf.num_workers=28 \
++dataset_conf.max_token_length=3000 \
++train_conf.max_epoch=50 \
++train_conf.log_interval=1 \
++train_conf.resume=true \
++train_conf.validate_interval=2000 \
++train_conf.save_checkpoint_interval=2000 \
++train_conf.keep_nbest_models=20 \
++train_conf.avg_nbest_model=20 \
++train_conf.use_deepspeed=false \
++train_conf.deepspeed_config=${deepspeed_config} \
++train_conf.avg_keep_nbest_models_type="loss" \
++optim_conf.lr=0.0002 \
++output_dir="${output_dir}" &> ${log_file}
注意在执行这个finetune.sh脚本的时候,使用下面的命令,这样启动就不会因为退出shell远程导致训练中断。
nohup ./finetune.sh > log.txt 2>&1 &
注意不要写为下面的这样,下面这样启动,在断开远程后会中断训练。
nohup bash finetune.sh > log.txt 2>&1 &
然后还需要启动tensorboard查看训练的loss曲线变化情况,可以使用下面的命令启动。
nohup tensorboard --host 0.0.0.0 --port 6007 --logdir /path/to/your/tf-logs/direction > tensorboard.log 2>&1 &
注意:需要将--logdir后面的值修改为你自己训练保存这个tensorboard的绝对路径。
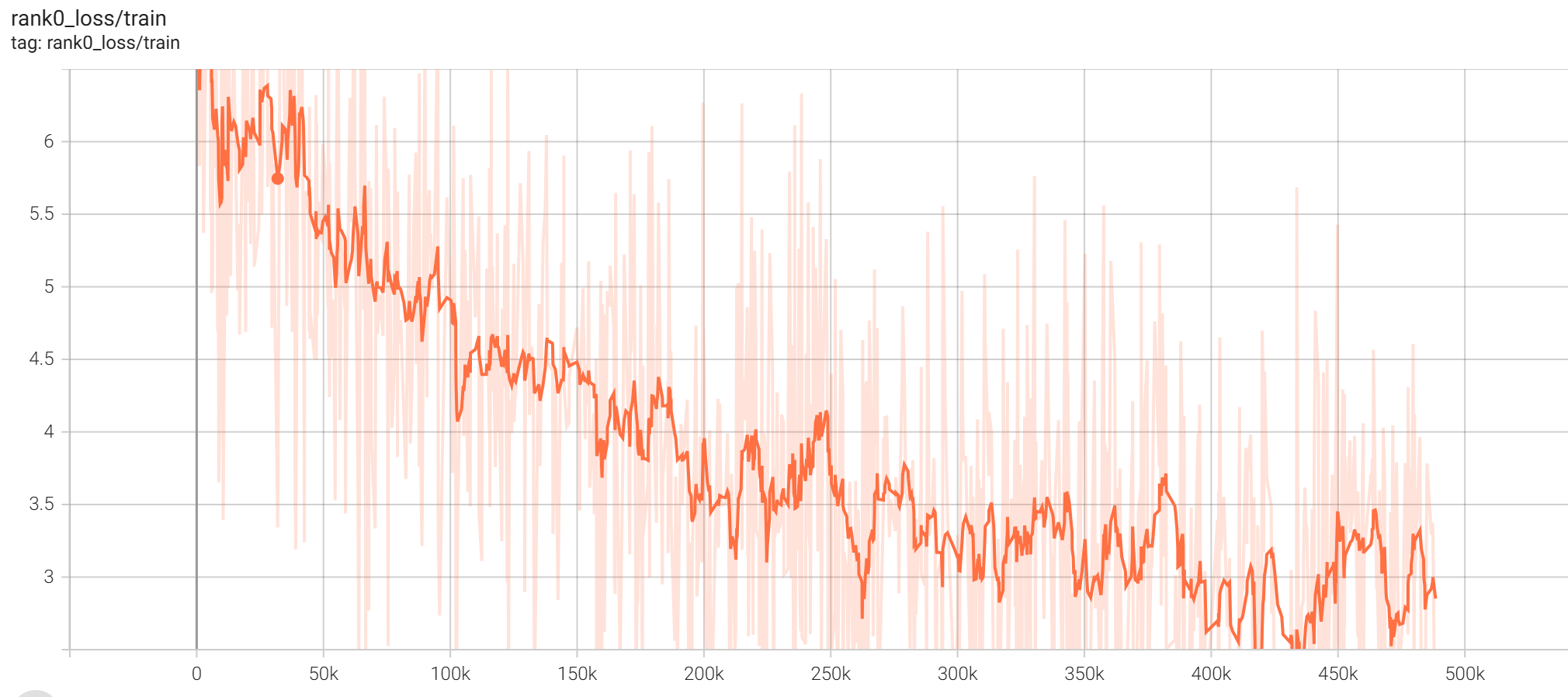
然后是在浏览器中访问你的局域网中的ip:6007就可以看到下面的内容了。一共训练了50轮次,耗时4.306天完成。下面是训练的loss变化曲线图。
4. 评估字错率
训练前后做对照实验,看看降低了多少的字错率。
| 测试集 | 训练前 | 训练后 |
|---|---|---|
| 普通话和河南话混合测试集 | CER = 0.12 | CER = 0.06 |
| 普通话测试集 | CER = 0.06 | CER = 0.05 |
| 河南话测试集 | CER = 0.13 | CER = 0.06 |
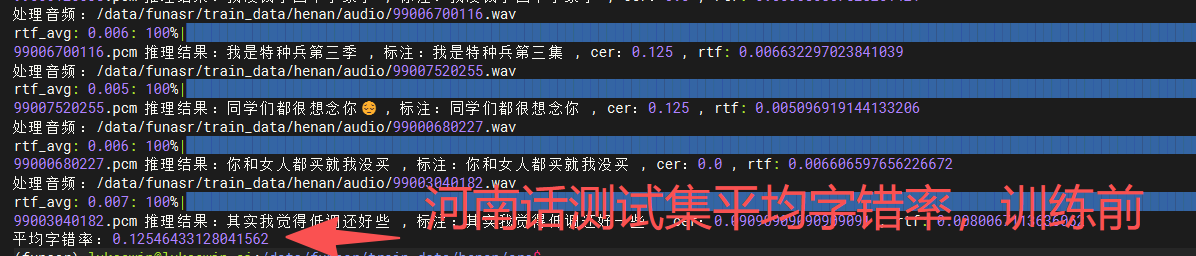

从上面的实际测评可以得出,训练之后,对河南话数据集字错率下降了7%,训练后最终准确率是94%。可以从表中得出,训练前后基本上对原先普通话的识别能力并没有影响,甚至提升了1%的准确率。
5. 其它
如果你想要训练其它方言,但是没有数据集,可以自己采集,可以用我基于SpringBoot和Vue开发的ASR数据集采集系统来采集,可以从下面的百度网盘中下。
通过网盘分享的文件:ASR数据集采集系统
链接: https://pan.baidu.com/s/10CBrLy4vJprwVQHzIbJv5Q?pwd=7utf 提取码: 7utf
如果你想要训练其它的方言模型,并且你不知道如何训练,可以联系lukeewin01进行有偿代训练。
Q.E.D.

