









1. 研究背景
在众多的开源ASR模型中,很多都称对国内很多方言可以识别,但经过实际测试,字错率太高无法商用。为了能进一步提升模型对特定方言的识别准确率,这里采集了一定数量的温州方言数据集,用于训练可以比较准确识别温州方言的ASR模型。
2. 运行环境
| CPU | GPU | 内存 | OS | CUDA |
|---|---|---|---|---|
| i7 14700KF 28核心 | 3090Ti 24GB | 64GB | ubuntu 24.04 | 12.8 |
3. 数据集说明
这里使用了24小时30分钟的温州方言数据集分为三部分,训练集、验证集和测试集,每个集合不存在交叉。
| 训练集 | 验证集 | 测试集 |
|---|---|---|
| 7532条 | 400条 | 100条 |
4. 训练模型
这里基于阿里开源的SenseVoiceSmall和Paraformer_Streaming两个模型进行了训练,下图是截图自训练实时语音识别模型Paraformer_Streaming的loss曲线变化图,以及对应的训练日志。
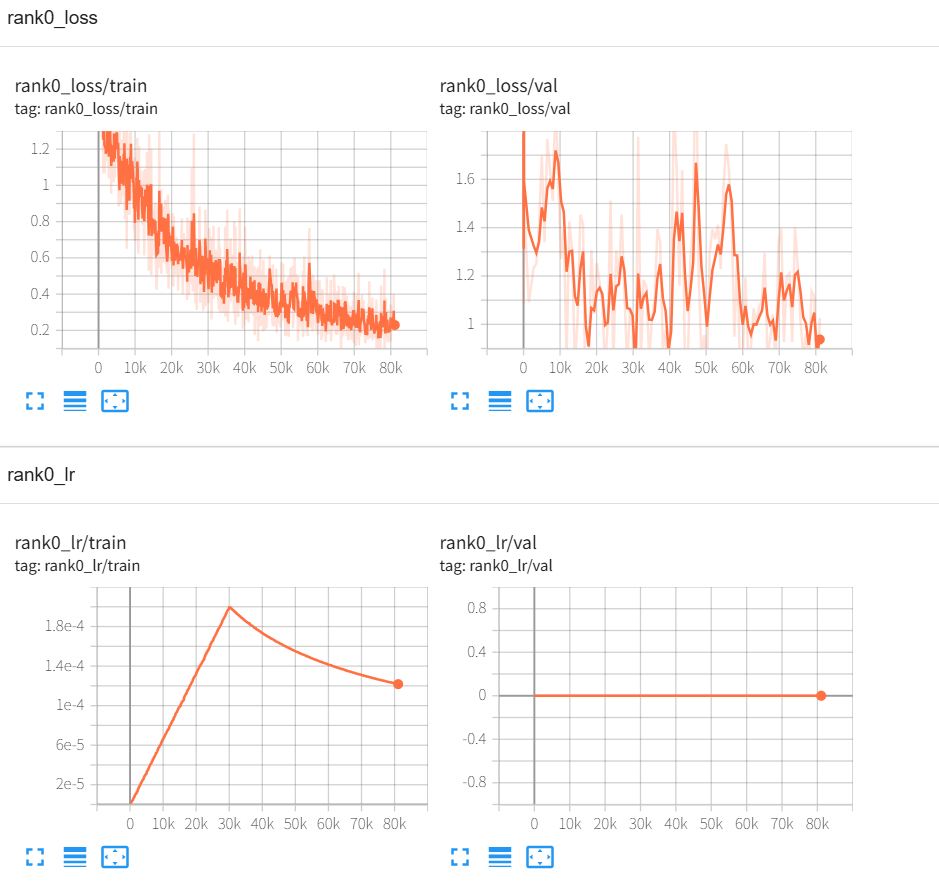
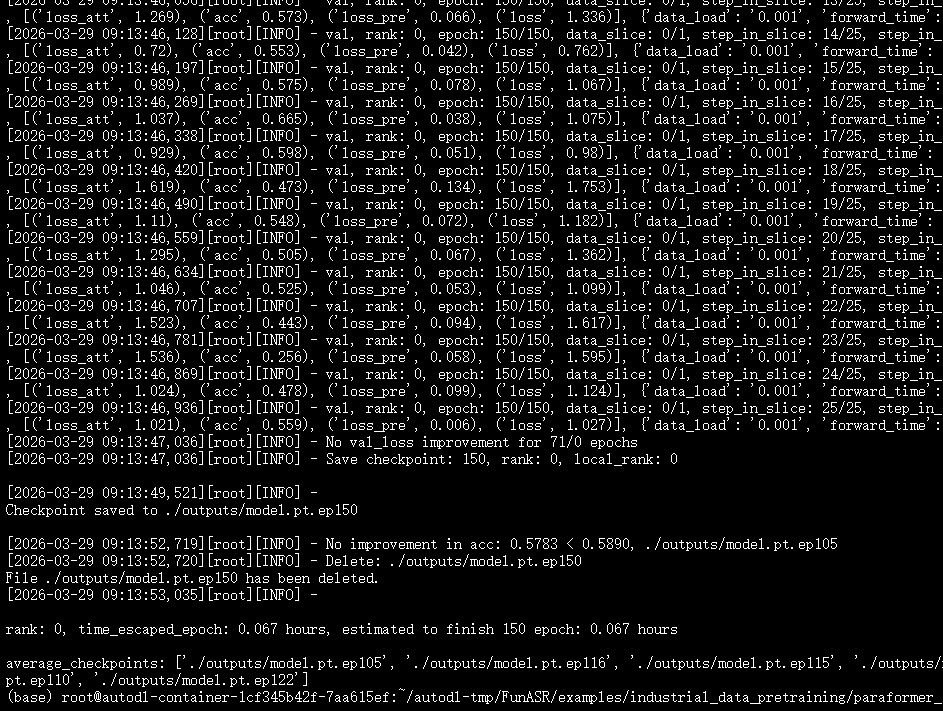
5. 字错率评估
这里只评估了非流式SenseVoiceSmall模型的字错率,其它非流式模型训练了两次,第一次训练后模型的字错率为23%,第二次字错率为20%。
下面是训练前后对照表格,cer越小越好
| 原生模型 | 第一次训练 | 第二次训练 |
|---|---|---|
| 0.94 | 0.23 | 0.20 |
评估真实截图如下所示:

下面是第一次训练后的评估真实截图:
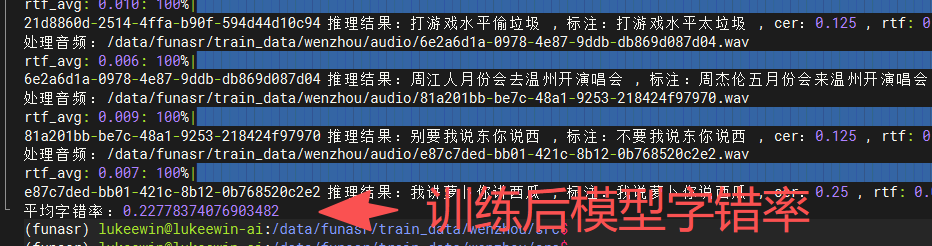
下图是第二次训练后的评估真实截图:
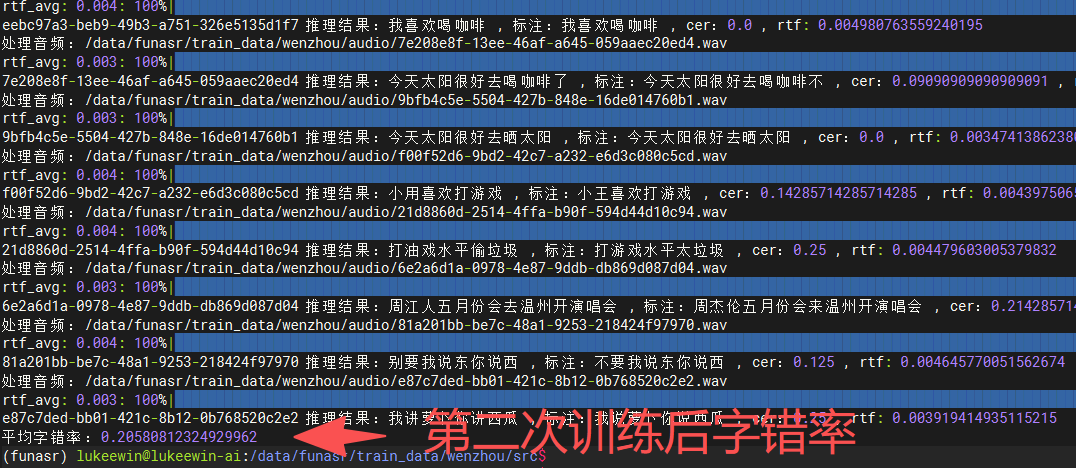
第一次和第二次训练主要是lr设置的不同,以及在第二次训练时,剔除了一条异常数据。
Q.E.D.

