









部署环境
| 显卡 | NVIDIA A100 | 20GB显存(这里没有租用完整一张显卡) |
|---|---|---|
| 内存 | 30GB | |
| 系统 | Ubuntu 24.04 | 需注意选择支持GPU的系统 |
如果想要购买已经构建好的Docker镜像,欢迎联系微信 lukeewin01。
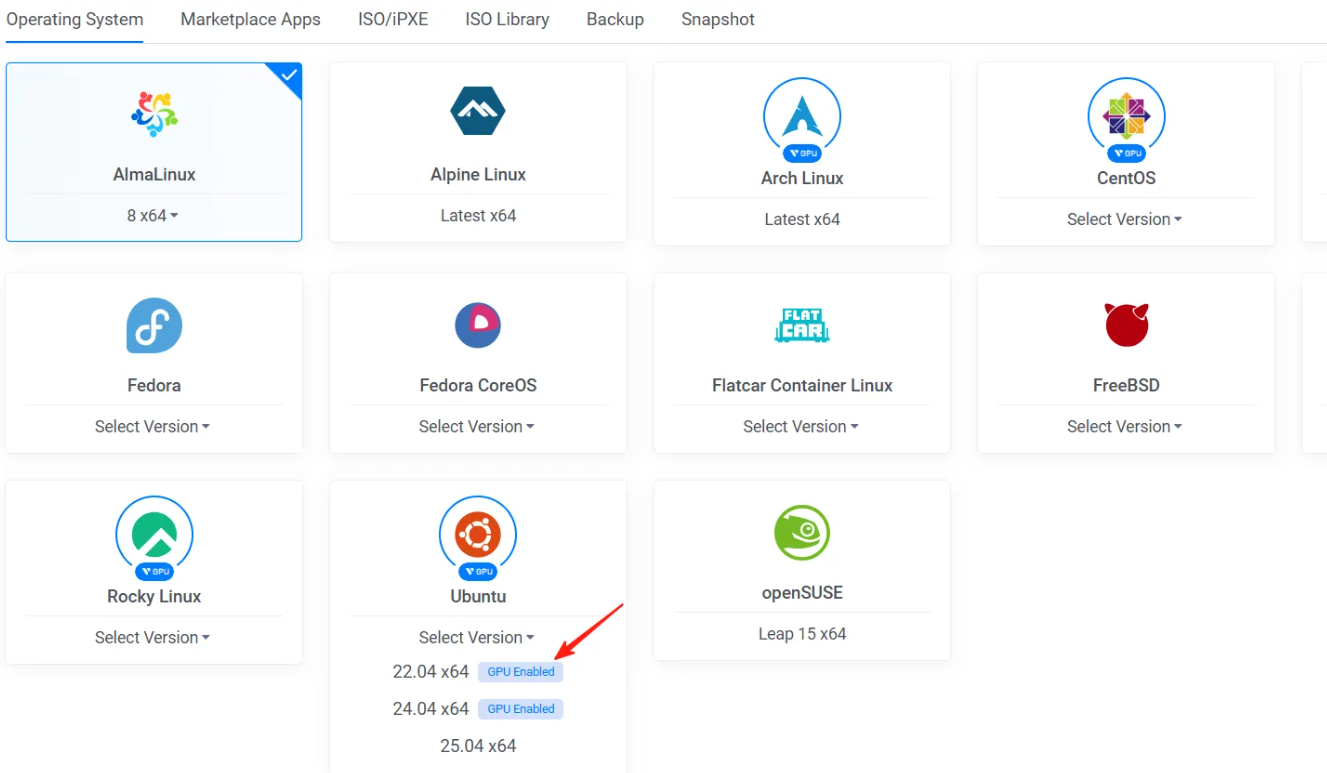
注意:部署时,需要选择支持GPU的系统,如看到下面截图中的标识,表明支持GPU。
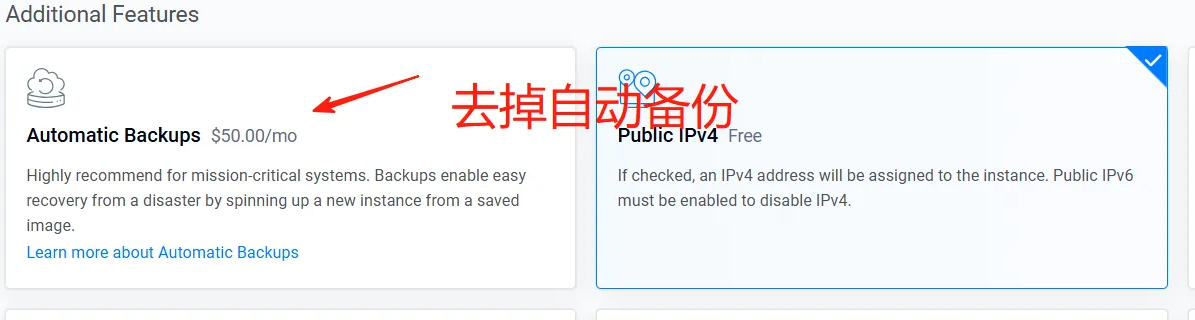
把默认勾选的“自动备份”功能去掉。当然你也可以保留,只是费用比较贵,我一般选择去掉。
然后点击“Deploy”,会自动安装系统。点击之后,会自动跳转到“Cloud Compute”页面中,在这个页面中可以看到目前已存在的服务器实例,如下图所示。

注意:如果你还没账号,可以点击"注册账号",只有注册并登录,才能选择服务器。
构建Docker镜像
经过上面的步骤,现在我们已经选择好了服务器,我只需要通过SSH连接工具远程连接到服务器中,然后进行构建Docker镜像操作即可。
注意:如果你使用的是国内的服务器来构建,会存在网络问题,这里推荐按照我文档中使用的服务器来构建,可以确保正确构建。如果还没服务器的,可以点击"注册账号"。
这里我使用开源的SSH工具WindTerm来远程连接到服务器,你也可以使用其它SSH工具。
apt-get update -y && apt update -y && apt-get upgrade -y
下载FunASR源码
git clone https://github.com/modelscope/FunASR.git
然后切换路径到triton_gpu路径中
cd FunASR/runtime/triton_gpu
要想构建Docker镜像,必须要先安装docker软件,如果还没安装的,可以按照下面命令安装。
注意:如果你使用的也是我上面说的这个服务器提供商的服务器,那么不需要安装了,自带安装好了docker。
开始构建镜像
docker build . -f Dockerfile/Dockerfile.sensevoice -t soar97/triton-sensevoice:24.05
注意:如果你不是使用我推荐的服务器,有可能会构建失败,大概率是网络问题。这里推荐使用我这篇文章推荐的服务器,如果还没注册,可以点击"注册账号"。
在构建过程中会报下面错误:
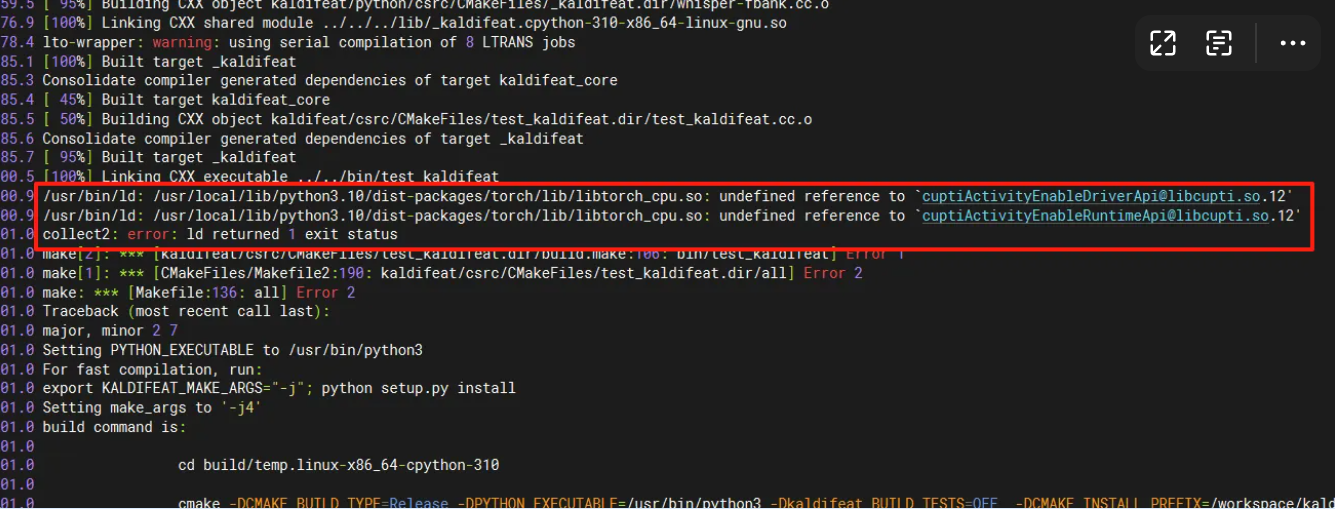
表明系统中缺少依赖,执行下面命令安装依赖。
如果还没安装cuda,要先安装cuda,可以执行下面命令。同时还需要安装cudnn,可以看我的博文,如何在Linux中安装CUDA和CUDNN
wget https://developer.download.nvidia.com/compute/cuda/12.4.1/local_installers/cuda_12.4.1_550.54.15_linux.run
sudo sh cuda_12.4.1_550.54.15_linux.run
vim ~/.bashrc
export PATH=/usr/local/cuda/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
source ~/.bashrc
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2404/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update
sudo apt-get -y install cudnn
sudo apt-get -y install cudnn-cuda-12
apt install -y cuda-cupti-12-0
复制这个动态链接库到 /usr/local/cuda/lib64 中。
cp /usr/local/cuda-12.4/extras/CUPTI/lib64/libcupti.so.12 /usr/local/cuda/lib64
如果还是一直构建失败,可以先跳过这步,等构建完成docker后,进入docker内容再安装。
在执行 RUN rm -r ./model_repo_sense_voice_small/.huggingface 时会报错,没有这个文件,可以把这个语句删掉。
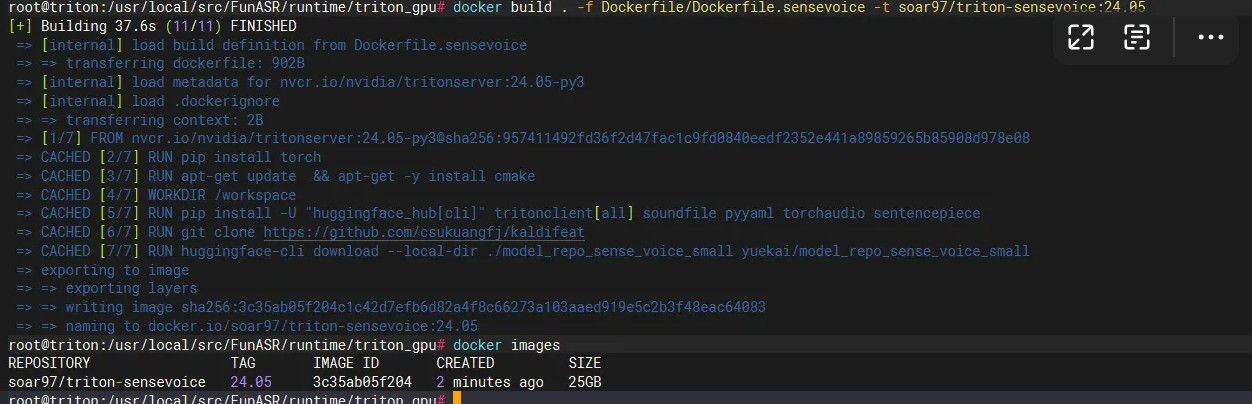
现在可以看到已经生成了docker镜像。
启动Docker容器
经过上一步骤,我们已经构建好了Docker镜像,现在我们需要执行下面命令来启动容器。
docker run -it --name "sensevoice-server" --gpus all --net host -v /mnt:/mnt --shm-size=2g soar97/triton-sensevoice:24.05
然后把第二步中剩下的步骤执行完成。
cd kaldifeat
sed -i 's/in running_cuda_version//g' get_version.py && python3 setup.py install
如果编译安装失败,重新编译之前需要把 build 目录删除掉,并且执行下面命令清除缓存。
pip install --no-cache-dir --force-reinstall -v .
如果还是报错,那么就需要卸载torch和torchaudio,重新安装,并且版本不能太高。
pip install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 --index-url https://download.pytorch.org/whl/cu118
然后再执行下面命令。
pip install --no-cache-dir --force-reinstall -v .
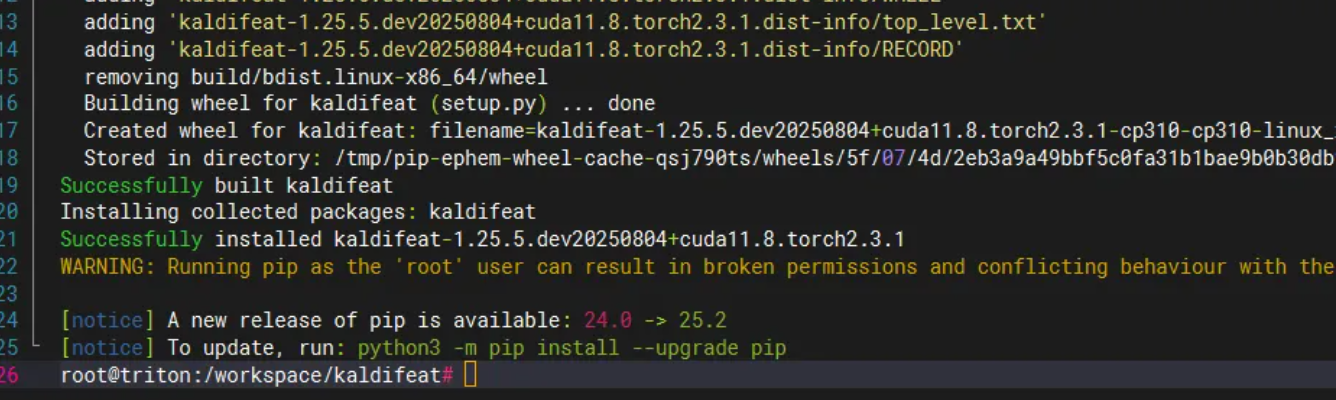
当看到下面截图的内容时,说明安装成功了,这说明安装的torch版本不能太高。
启动SenseVoiceSmall接口
cd /workspace/model_repo_sense_voice_small
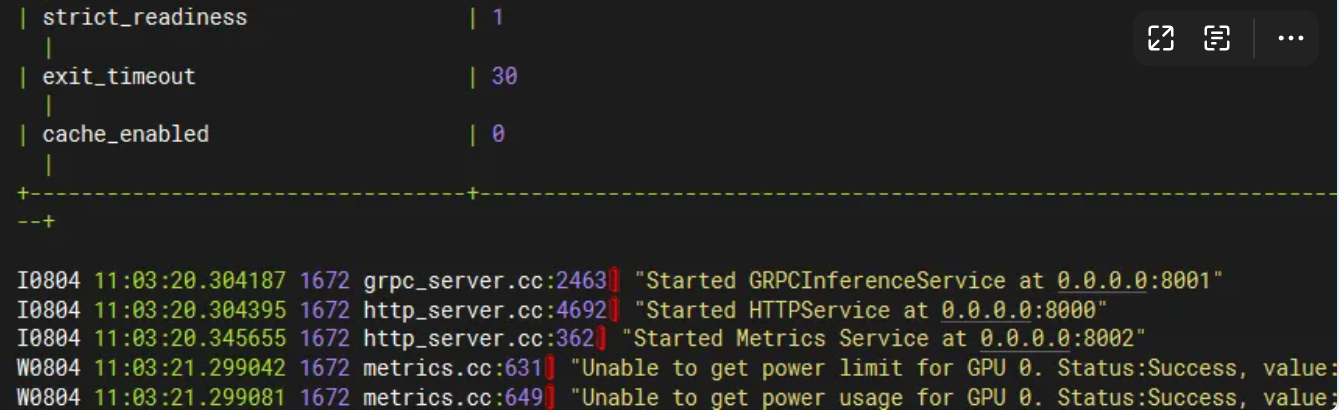
nohup bash run.sh > log.txt 2>&1 &
现在就启动好了,如下图所示。
测试接口
git clone https://github.com/yuekaizhang/Triton-ASR-Client.git
cd Triton-ASR-Client
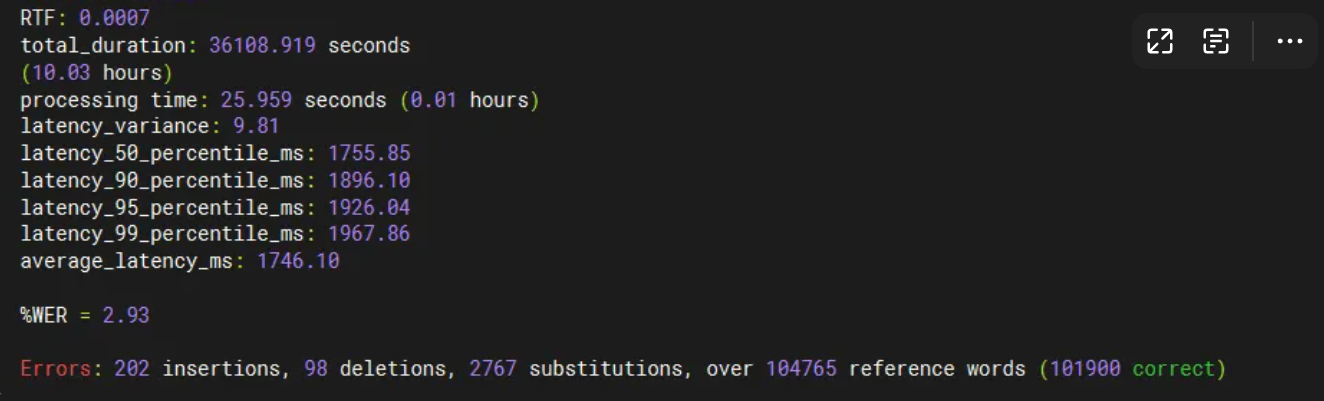
python3 client.py \
--server-addr localhost \
--server-port 8001 \
--model-name sensevoice \
--compute-cer \
--num-tasks 32 \
--batch-size 16 \
--manifest-dir ./datasets/aishell1_test
在执行安装依赖时会报错,需要使用conda环境。
conda create -n triton_client python=3.10
conda activate triton_client
pip install -r requirements.txt
报下面错误
ValueError: manifest_dir ./datasets/aishell1_test should contain wav files
是因为路径有问题,把aishell1_test中的data_aishell里的wav复制到aishell1_test中。并且还需要修改 wav.scp 中的路径。
导出镜像
docker save -o triton-sensevoice.tar triton-sensevoice:25.08
由于导出的镜像很大,这里压缩一下。
tar -czvf triton-sensevoice.tar.gz triton-sensevoice.tar
压缩之后还是很大,不方便传输,这里使用下面命令进行拆分。
split -b 2048m triton-sensevoice.tar.gz
使用上面命令会生成下面几个文件。
xaa xab xac xad xae xaf xag xah xai xaj
对每个文件计算hash值,防止在传递过程中缺失内容。
for file in xa*; do sha256sum "$file" > "$file.sha256"; done
同时也计算拆分前的hash值。
sha256sum triton-sensevoice.tar.gz > triton-sensevoice.tar.gz.sha256
现在就可以拷贝到其它服务器中了。
导入镜像
导入之前先合并,然后解压,验证hash是否正确
cat xa* > triton-sensevoice.tar.gz
for file in xa*; do
sha256sum -c "$file.sha256"
done
sha256sum -c triton-sensevoice.tar.gz.sha256
tar -zxvf triton-sensevoice.tar.gz
docker load -i triton-sensevoice.tar
Q.E.D.

