









1. 研究背景
在会议场景中,我们通常需要做会议纪要,并且最好是实时会议纪要,也就是领导一边讲话,系统应该一边出文字,同时可以做到区分说话人,并且是无需提前注册声纹信息,使用SPK标识。
Fun-ASR-Nano这个模型更好可以做到这些,可以实时转写为文字,然后区分说话人使用的是另外的一个模型,我们只需要安装FunASR就可以方便使用这些模型,这个依赖中已经帮我们集成好了语音识别模型和声纹模型。
2. 硬件和软件
2.1 硬件
显卡使用的是英伟达的A40显卡,这里只租了1/6张显卡,也就是8GB显存,这也是跑这个项目要求的最低显存。
这里选择vultr服务器,因为下载资料更快。点击这里跳转到服务器。
首先进入到vultr控制台中,找到左侧的Complute菜单中的Instances,然后点击右上角的Create Instance
点击进入之后,再点击Cloud GPU,如下图。
然后选择一个NVIDIA显卡,这里选择A40的显卡,并且为了节省资金,只选择了8GB的显卡,也就是1/6张A40显卡。
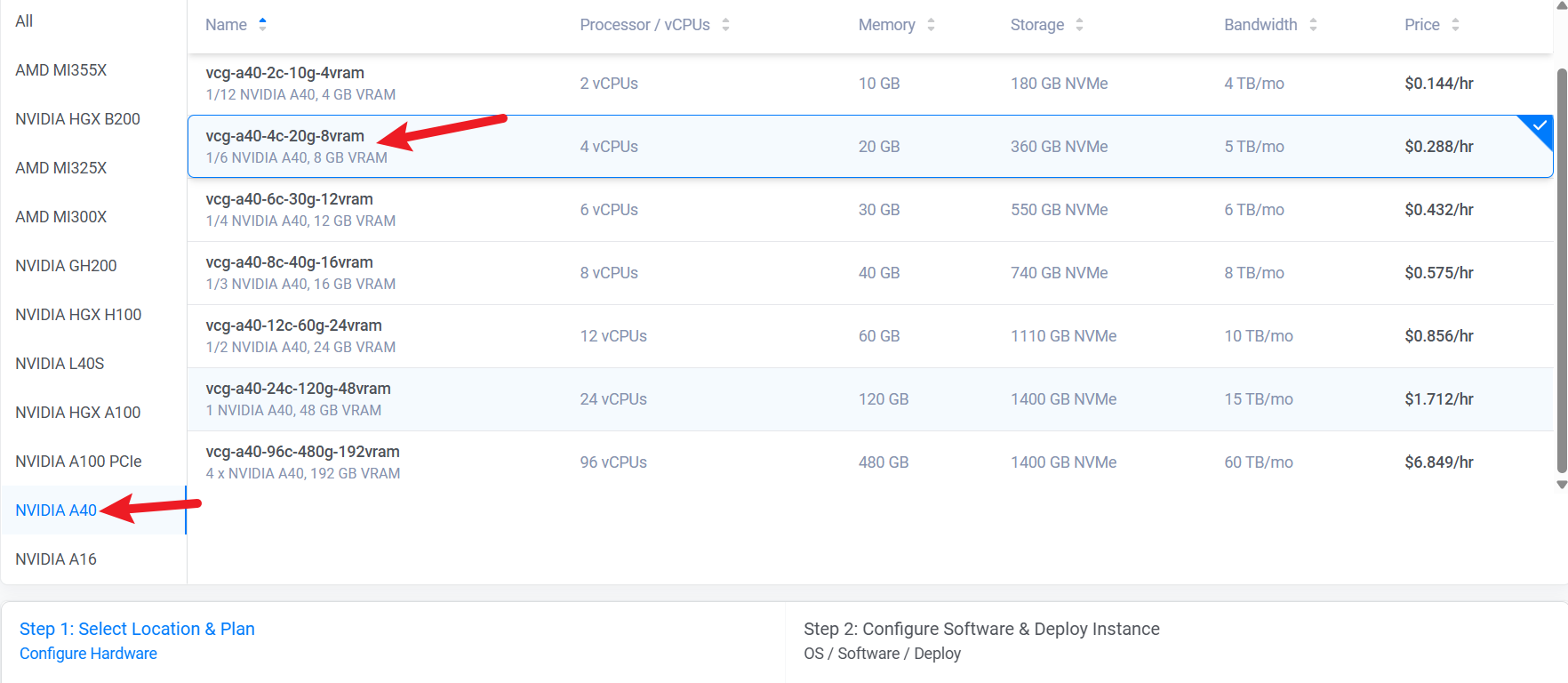
硬件情况是8GB显存,20GB运行内存,4核心CPU,360GB硬盘。
2.2 软件
上面选择完了硬件,现在选择一下软件方面的。
点击下面的Step 2 Configure Software & Deploy Instance
然后选择操作系统,这里选择Ubuntu 24.04

这里一定要注意要选择支持GPU的系统,也就是图标上有GPU标识的系统,并且系统版本也要选择有GPU Enabled标识的。如上图所示。
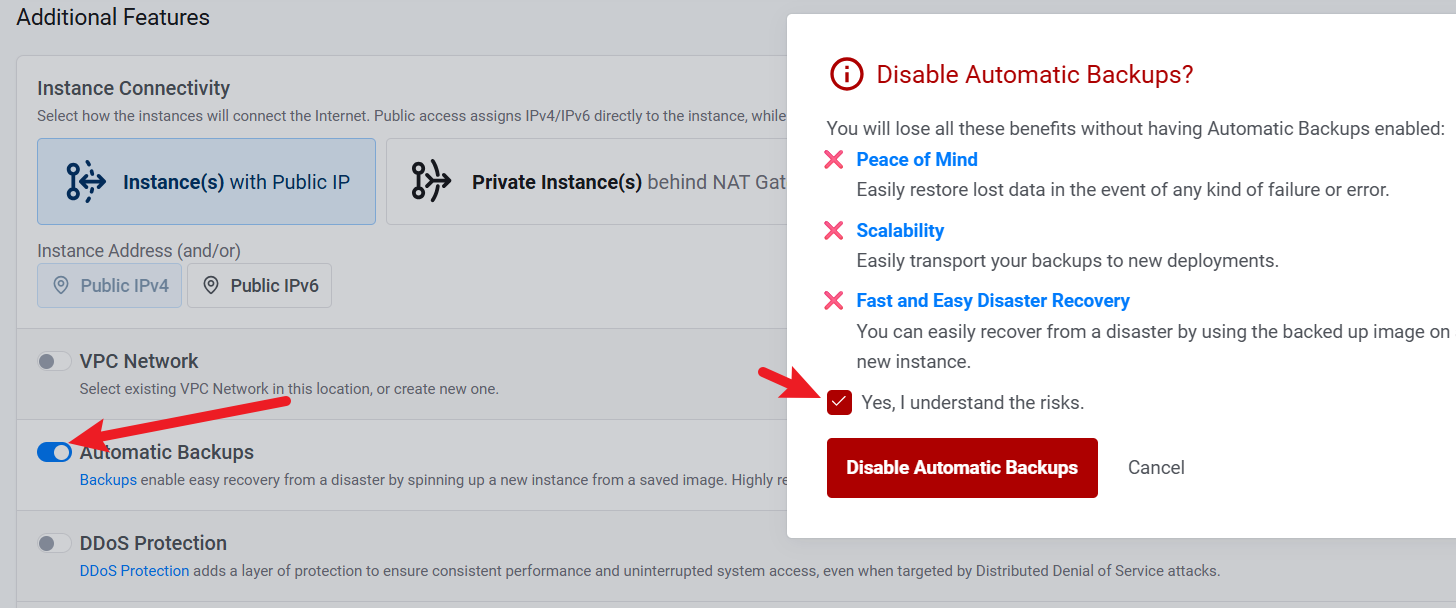
最后要记得把Automatic Backups关闭,否则扣费很高。
3. 环境安装
3.1 安装CUDA
vultr默认只安装了显卡驱动,我们需要根据显卡驱动来安装对应版本的CUDA。
首先查看NVIDIA驱动,可以使用下面的命令。
nvidia-smi
可以看到如下截图
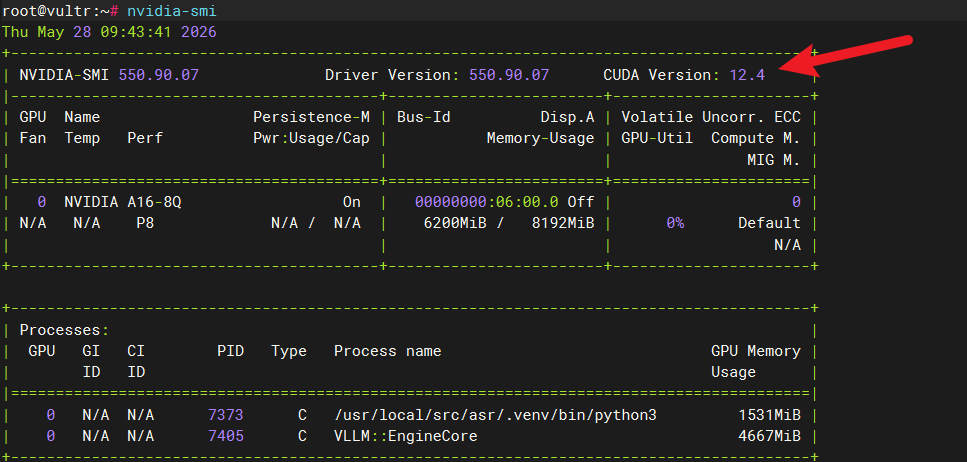
这里可以看到最高支持12.4版本的CUDA。那么这里我们就下载这个版本的CUDA。
可以访问官方网站下载,下面直接给出下载和安装命令。
wget https://developer.download.nvidia.com/compute/cuda/12.4.1/local_installers/cuda_12.4.1_550.54.15_linux.run
chmod +x cuda_12.4.1_550.54.15_linux.run
./cuda_12.4.1_550.54.15_linux.run
安装的时候把显卡驱动去掉,其它的默认即可。
安装完成之后还要记得配置系统环境变量。
vim ~/.bashrc
在文本的末尾添加下面的内容。
export PATH=/usr/local/cuda-12.4/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.4/lib64:$LD_LIBRARY_PATH
最后还要记得执行下面命令或者重新进入ssh。
source ~/.bashrc
检查是否配置成功。
nvcc -V
3.2 安装Python环境
这里使用uv作为python项目管理工具,你也可以用Minconda。
安装uv,使用下面命令
curl -LsSf https://astral.sh/uv/install.sh | sh
安装完成之后也一样需要执行下面命令才能生效。
source ~/.bashrc
最后检查一下是否安装配置成功,执行下面的命令。
uv --version
创建指定python版本的项目
mkdir asr && cd asr && uv venv --python 3.12 && source .venv/bin/activate
3.3 源码编译安装FunASR
这里使用源码编译方式安装FunASR,先拉取源码。
git clone https://github.com/modelscope/FunASR.git
然后执行下面命令安装。
uv pip install -e ./
安装完成之后验证一下。
uv pip show funasr
3.4 安装vLLM
这里一定要主要安装的版本不能过低也不能过高,经过验证0.12.0这个版本是可以的,并且对应的torch版本是2.9.0。
执行下面的命令安装vllm。
uv pip install vllm==0.12.0
验证一下是否安装成功。
uv pip show vllm
4. 启动接口
uv run python serve_realtime_ws.py \
--port 10095 \
--model FunAudioLLM/Fun-ASR-Nano-2512 \
--hub hf \
--device cuda:0 \
--decode-interval 0.48 \
--hotword-file 热词列表 \
--language 中文 \
--dtype bf16 \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.8 \
--max-model-len 2048
上面这个是在一张显卡中运行的,如果有多张显卡,就修改tensor-parallel-size的值,想要用几张显卡就填写数字几。
如果显存不够,可以修改gpu-memory-utilization的值,和修改max-model-len的值。
5. 测试效果
上面启动了服务端接口后就可以在本地启动客户端测试了,有两种方式,一种是通过浏览器来测试,另外一种是直接跑客户端python代码来测试。这里选择第一种,使用浏览器方式来测试。
由于我是部署到服务器中的,并且并没有使用SSL证书,如果想要浏览器可以实时获取音频流数据,就必须将服务器地址映射到本地,也就是穿透到本地,这样访问接口,就可以直接使用localhost或者127.0.0.1。
下面是穿透的命令。
ssh -CNg -L 10095:127.0.0.1:10095 root@your_ip
如果你修改过ssh的端口,可以在上面的命令后添加参数-p your_port。
具体演示效果,可以看我之前录制的发布到我B站账号的视频,点击这里跳转到演示视频处。

Q.E.D.

